Guia de Referência do Apache Kafka
Este guia de referência demonstra como sua aplicação Quarkus pode utilizar a Mensageria Quarkus para interagir com o Apache Kafka.
1. Introdução
O Apache Kafka é uma plataforma popular de streaming de eventos distribuídos de código aberto. É comumente usado para pipelines de dados de alto desempenho, análise de streaming, integração de dados e aplicações de missão crítica. Semelhante a uma fila de mensagens ou a uma plataforma de mensagens corporativas, ele permite que você:
-
publique (escreva) e assine (leia) fluxos de eventos, chamados de registros.
-
armazene fluxos de registros de forma durável e confiável dentro de tópicos.
-
processe fluxos de registros à medida que eles ocorrem ou retrospectivamente.
E toda esta funcionalidade é fornecida de uma forma distribuída, altamente escalável, elástica, tolerante a falhas e segura.
2. Extensão Quarkus para Apache Kafka
O Quarkus oferece suporte para Apache Kafka através do framework Mensageria Reativa do SmallRye. Baseado na especificação Eclipse MicroProfile Reactive Messaging 2.0, ela propõe um modelo de programação flexível que conecta CDI e processamento orientado a eventos.
|
Este guia fornece uma visão aprofundada sobre Apache Kafka e o framework SmallRye Reactive Messaging. Para um início rápido, consulte Introdução à Mensageria Quarkus com Apache Kafka. |
Você pode adicionar a extensão messaging-kafka ao seu projeto executando o seguinte comando no diretório base do seu projeto:
quarkus extension add messaging-kafka./mvnw quarkus:add-extension -Dextensions='messaging-kafka'./gradlew addExtension --extensions='messaging-kafka'Isto adicionará o seguinte ao seu arquivo de build:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-messaging-kafka</artifactId>
</dependency>implementation("io.quarkus:quarkus-messaging-kafka")|
The extension includes |
3. Configurando conector Kafka SmallRye
Como a estrutura SmallRye Reactive Messaging é compatível com diferentes back-ends de mensagens, como Apache Kafka, AMQP, Apache Camel, JMS, MQTT etc., ela emprega um vocabulário genérico:
-
Aplicações enviam e recebem mensagens. Uma mensagem encapsula um payload e pode ser estendida com alguns metadados. Com o conector Kafka, uma mensagem corresponde a um registro Kafka.
-
As mensagens transitam nos canais. Os componentes da aplicação ligam-se aos canais para publicar e consumir mensagens. O conector Kafka mapeia canais para tópicos Kafka.
-
Os canais são ligados a backends de mensagens através de conectores. Os conectores são configurados para mapear as mensagens de entrada para um canal específico (consumido pela aplicação) e recolher as mensagens de saída enviadas para um canal específico. Cada conector é dedicado a uma tecnologia de mensagens específica. Por exemplo, o conector que lida com o Kafka tem o nome de
smallrye-kafka.
Uma configuração mínima para o conector Kafka com um canal de entrada tem o seguinte aspecto:
%prod.kafka.bootstrap.servers=kafka:9092 (1)
mp.messaging.incoming.prices.connector=smallrye-kafka (2)| 1 | Configure a localização do broker para o perfil de produção. Você pode configurá-lo globalmente ou por canal usando a propriedade mp.messaging.incoming.$channel.bootstrap.servers. No modo de desenvolvimento e ao executar testes, Dev Services para o Kafka inicia automaticamente um broker Kafka. Quando não fornecida, esta propriedade tem o valor padrão localhost:9092. |
| 2 | Configure o conector para gerenciar o canal de preços. Por padrão, o nome do tópico é o mesmo que o nome do canal. Você pode configurar o atributo do tópico para o substituir. |
O prefixo %prod indica que a propriedade só é utilizada quando a aplicação é executada em modo de produção (portanto, não em desenvolvimento ou teste). Consulte a documentação do Perfil para obter mais detalhes.
|
|
Fixação automática do conector
Se você tiver um único conector no classpath, poderá omitir a configuração do atributo Esta ligação automática pode ser desativada utilizando: |
4. Recebendo mensagens do Kafka
Continuando com a configuração mínima anterior, a sua aplicação Quarkus pode receber diretamente a conteúdo da mensagem:
import org.eclipse.microprofile.reactive.messaging.Incoming;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class PriceConsumer {
@Incoming("prices")
public void consume(double price) {
// process your price.
}
}Existem várias outras formas da sua aplicação consumir mensagens recebidas:
@Incoming("prices")
public CompletionStage<Void> consume(Message<Double> msg) {
// access record metadata
var metadata = msg.getMetadata(IncomingKafkaRecordMetadata.class).orElseThrow();
// process the message payload.
double price = msg.getPayload();
// Acknowledge the incoming message (commit the offset)
return msg.ack();
}O tipo Message permite que o método consumidor acesse os metadados da mensagem recebida e manipule a confirmação manualmente. Iremos explorar diferentes estratégias de confirmação em Estratégias de Confirmação.
Se você pretende acessar diretamente os objetos do registro Kafka, utilize:
@Incoming("prices")
public void consume(ConsumerRecord<String, Double> record) {
String key = record.key(); // Can be `null` if the incoming record has no key
String value = record.value(); // Can be `null` if the incoming record has no value
String topic = record.topic();
int partition = record.partition();
// ...
}ConsumerRecord é fornecido pelo cliente Kafka subjacente e pode ser injetado diretamente no método do consumidor. Outra abordagem mais simples consiste em usar Record:
@Incoming("prices")
public void consume(Record<String, Double> record) {
String key = record.key(); // Can be `null` if the incoming record has no key
String value = record.value(); // Can be `null` if the incoming record has no value
}Record é um simples encapsulador em torno da chave e do conteúdo do registro Kafka recebido.
Alternativamente, sua aplicação pode injetar um Multi no seu bean e assinar os seus eventos, como no exemplo seguinte:
import io.smallrye.mutiny.Multi;
import org.eclipse.microprofile.reactive.messaging.Channel;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.jboss.resteasy.reactive.RestStreamElementType;
@Path("/prices")
public class PriceResource {
@Inject
@Channel("prices")
Multi<Double> prices;
@GET
@Path("/prices")
@RestStreamElementType(MediaType.TEXT_PLAIN)
public Multi<Double> stream() {
return prices;
}
}Esse é um bom exemplo de como integrar um consumidor Kafka com outro downstream, neste exemplo, expondo-o como um endpoint Server-Sent Events.
|
Ao consumir mensagens com |
Os seguintes tipos podem ser injetados como canais:
@Inject @Channel("prices") Multi<Double> streamOfPayloads;
@Inject @Channel("prices") Multi<Message<Double>> streamOfMessages;
@Inject @Channel("prices") Publisher<Double> publisherOfPayloads;
@Inject @Channel("prices") Publisher<Message<Double>> publisherOfMessages;Assim como no exemplo anterior com Message, se o seu canal injetado recebe payloads (Multi<T>), ele reconhece a mensagem automaticamente e suporta múltiplos assinantes. Se o seu canal injetado recebe Mensagem (Multi<Message<T>>), você será responsável pela confirmação e transmissão. Iremos explorar o envio de mensagens de transmissão em Difusão de mensagens em vários consumidores.
|
Injetar |
4.1. Bloqueando o processamento
A Mensageria Reativa invoca seu método em um thread de E/S. Consulte a documentação da Arquitetura Reativa do Quarkus para obter mais detalhes sobre esse tópico. Mas, muitas vezes, você precisa combinar o envio de mensagens reativas com processamento blocante, como interações de banco de dados. Para isso, você precisa usar a anotação @Blocking indicando que o processamento está bloqueando e não deve ser executado no thread do chamador.
Por exemplo, o código a seguir ilustra como é possível armazenar conteúdos recebidos em uma base de dados usando o Hibernate com Panache:
import io.smallrye.reactive.messaging.annotations.Blocking;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.transaction.Transactional;
@ApplicationScoped
public class PriceStorage {
@Incoming("prices")
@Transactional
public void store(int priceInUsd) {
Price price = new Price();
price.value = priceInUsd;
price.persist();
}
}O exemplo completo está disponível nodiretório kafka-panache-quickstart.
|
Existem 2 anotações de
Eles têm o mesmo efeito. Portanto, você pode usar os dois. O primeiro fornece um ajuste mais refinado, como o pool de trabalho a ser usado e se ele preserva a ordem. O segundo, usado também com outros recursos reativos do Quarkus, usa o pool de trabalho padrão e preserva a ordem. Informações detalhadas sobre a utilização da anotação |
|
@RunOnVirtualThread
Para executar o processamento blocante em threads virtuais Java, consulte a documentação de suporte do Quarkus à Virtual Thread com Mensageria Reativa. |
|
@Transactional
Se o seu método estiver anotado com |
4.2. Estratégias de Reconhecimento
Todas as mensagens recebidas por um consumidor devem ser confirmadas. Na ausência de confirmação, o processamento é considerado um erro. Se o método do consumidor receber um Record ou um conteúdo, a mensagem será confirmada no retorno do método, também conhecido como Strategy.POST_PROCESSING. Se o método do consumidor retornar outro fluxo reativo ou CompletionStage, a mensagem será confirmada quando a mensagem downstream for confirmada. Você pode substituir o comportamento padrão para acessar a mensagem na chegada (Strategy.PRE_PROCESSING) ou não acessar a mensagem de forma alguma (Strategy.NONE) no método do consumidor, como no exemplo a seguir:
@Incoming("prices")
@Acknowledgment(Acknowledgment.Strategy.PRE_PROCESSING)
public void process(double price) {
// process price
}Se o método consumidor receber uma Message, a estratégia de reconhecimento será Strategy.MANUAL e o método consumidor será responsável por reconhecer/não reconhecer a mensagem.
@Incoming("prices")
public CompletionStage<Void> process(Message<Double> msg) {
// process price
return msg.ack();
}Como mencionado acima, o método também pode substituir a estratégia de confirmação para PRE_PROCESSING ou NONE.
4.3. Estratégias de Confirmação
Quando uma mensagem produzida a partir de um registro do Kafka é reconhecida, o conector invoca uma estratégia de confirmação. Essas estratégias decidem quando o deslocamento do consumidor para um tópico/partição específico é confirmado. A confirmação de um deslocamento indica que todos os registros anteriores foram processados. É também a posição em que a aplicação reiniciaria o processamento após uma recuperação de falha ou uma reinicialização.
A confirmação de cada deslocamento tem penalidades de desempenho, pois o gerenciamento de deslocamento do Kafka pode ser lento. No entanto, não confirmar o deslocamento com frequência suficiente pode levar à duplicação de mensagens se a aplicação falhar entre duas confirmações.
O conector Kafka suporta três estratégias:
-
throttledmantém o controle das mensagens recebidas e confirma um deslocamento da última mensagem recebida em sequência (ou seja, todas as mensagens anteriores também foram recebidas). Essa estratégia garante a entrega pelo menos uma vez, mesmo que o canal execute o processamento assíncrono. O conector rastreia os registros recebidos e periodicamente (período especificado porauto.commit.interval.ms, padrão: 5000 ms) confirma o maior deslocamento consecutivo. O conector será marcado como não saudável se uma mensagem associada a um registro não for confirmada emthrottled.unprocessed-record-max-age.ms(padrão: 60000 ms). Na verdade, essa estratégia não pode confirmar o deslocamento assim que houver falha no processamento de um único registro. Sethrottled.unprocessed-record-max-age.msfor definido como menor ou igual a0, ele não realizará nenhuma verificação de integridade. Essa configuração pode levar à falta de memória se houver mensagens do tipo "pílula de veneno" (que nunca são aceitas). Essa estratégia é o padrão seenable.auto.commitnão estiver explicitamente definido como verdadeiro. -
checkpointpermite persistir os offsets do consumidor em um state store, em vez de registra-los de volta para o broker Kafka. Usando a APICheckpointMetadata, o código do consumidor pode persistir um processing state com o offset do registro para marcar o progresso de um consumidor. Quando o processamento continua a partir de um offset previamente persistido, ele posiciona o consumidor Kafka nesse offset e também restaura o estado persistido, continuando o processamento com estado de onde parou. A estratégia de checkpoint mantém localmente o estado de processamento associado ao último offset e o persiste periodicamente no state store (período especificado porauto.commit.interval.ms(padrão: 5000)). O conector será marcado como não saudável se nenhum estado de processamento for persistido no state store emcheckpoint.unsynced-state-max-age.ms(padrão: 10000). Secheckpoint.unsynced-state-max-age.msfor definido como menor ou igual a 0, ele não realizará nenhuma verificação de saúde. Para mais informações, consulte Processamento com estado com Ponto de Verificação -
latestconfirma o offset do registro recebido pelo consumidor Kafka assim que a mensagem associada é reconhecida (se o offset for maior que o offset previamente confirmado). Esta estratégia fornece entrega pelo menos uma vez se o canal processa a mensagem sem realizar nenhum processamento assíncrono. Especificamente, o offset da mensagem mais recentemente reconhecida sempre será confirmado, mesmo que mensagens mais antigas ainda não tenham terminado de ser processadas. Em caso de incidente, como uma falha, o processamento reiniciaria após o último commit, resultando em mensagens mais antigas que nunca foram processadas com sucesso e completamente, o que poderia ser interpretado como perda de mensagem. Esta estratégia não deve ser usada em um ambiente de carga alta, pois a confirmação do offset é custosa. No entanto, ela reduz o risco de duplicatas. -
ignorenão realiza nenhuma confirmação. Essa estratégia é a estratégia padrão quando o consumidor é configurado explicitamente comenable.auto.commitcomo true. Ela delega a confirmação de deslocamento para o cliente Kafka subjacente. Quandoenable.auto.commitétrue, essa estratégia NÃO garante a entrega pelo menos uma vez. A Mensageria Reativa do SmallRye processa registros de forma assíncrona, de modo que os deslocamentos podem ser confirmados para registros que foram pesquisados, mas ainda não processados. Em caso de falha, apenas os registros que ainda não foram confirmados serão reprocessados.
|
O conector Kafka desativa a confirmação automática do Kafka quando ela não está explicitamente ativada. Esse comportamento difere do consumidor tradicional do Kafka. Se a alta taxa de transferência for importante para você, e se não estiver limitado pelo downstream, recomendamos:
|
O SmallRye Reactive Messaging permite a implementação de estratégias de commit personalizadas. Consulte a documentação do SmallRye Reactive Messaging para obter mais informações.
4.4. Estratégias de Tratamento de Erros
If a message produced from a Kafka record is nacked, a failure strategy is applied. The Kafka connector supports the following strategies:
-
fail: falha a aplicação, não serão processados mais registros (estratégia padrão). O deslocamento do registro que não foi processado corretamente não é confirmado. -
ignore: a falha é registrada, mas o processamento continua. O deslocamento do registro que não foi processado corretamente é confirmado. -
dead-letter-queue: o deslocamento do registro que não foi processado corretamente é confirmado, mas o registro é escrito em um tópico de letra morta do Kafka. -
delayed-retry-topic: the failed record is sent to delayed retry topics for later reprocessing, with configurable delays and maximum retries.
A estratégia é selecionada utilizando o atributo failure-strategy.
No caso do dead-letter-queue, você pode configurar os seguintes atributos:
-
dead-letter-queue.topic: o tópico usado para escrever os registros não processados corretamente, o padrão édead-letter-topic-$channel, sendo$channelo nome do canal. -
dead-letter-queue.key.serializer: o serializador usado para escrever a chave de registro na fila de letra morta. Por padrão, o serializador é deduzido a partir do desserializador da chave. -
dead-letter-queue.value.serializer: o serializador usado para escrever o valor do registro na fila de letras mortas. Por padrão, o serializador é deduzido a partir do desserializador do valor.
O registro escrito na fila de cartas mortas contém um conjunto de cabeçalhos adicionais sobre o registro original:
-
dead-letter-reason: o motivo da falha
-
dead-letter-cause: a causa da falha, se houver
-
dead-letter-topic: o tópico original do registro
-
dead-letter-partition: a partição original do registro (inteiro mapeado para String)
-
dead-letter-deslocamento: o deslocamento original do registro (long mapeado para String)
O SmallRye Reactive Messaging permite a implementação de estratégias de falha personalizadas. Consulte a documentação do SmallRye Reactive Messaging para obter mais informações.
4.4.1. Repetindo o processamento
Você pode combinar a Mensageria Reativa com a Tolerância a Falhas do SmallRye e tentar novamente o processamento em caso de falha:
@Incoming("kafka")
@Retry(delay = 10, maxRetries = 5)
public void consume(String v) {
// ... retry if this method throws an exception
}Você pode configurar o atraso, o número de tentativas, o jitter, etc.
Se o método devolver um Uni ou CompletionStage, é necessário acrescentar a anotação @NonBlocking:
@Incoming("kafka")
@Retry(delay = 10, maxRetries = 5)
@NonBlocking
public Uni<String> consume(String v) {
// ... retry if this method throws an exception or the returned Uni produce a failure
}
A anotação @NonBlocking só é necessária com a Tolerância a Falha do SmallRye 5.1.0 e versões anteriores. A partir da Tolerância a Falha do SmallRye 5.2.0 (disponível desde o Quarkus 2.1.0.Final), ela não é necessária. Consulte a documentação da Tolerância a Falha do SmallRye para obter mais informações.
|
As mensagens recebidas são reconhecidas somente quando o processamento é concluído com êxito. Portanto, ele confirma o deslocamento após o processamento bem-sucedido. Se o processamento ainda falhar, mesmo depois de todas as tentativas, a mensagem será não reconhecida e a estratégia de falha será aplicada.
4.4.2. Tratando Falhas de Desserialização
Quando ocorre uma falha na desserialização, você pode interceptá-la e fornecer uma estratégia de falha. Para isso, você precisa criar um bean que implemente a interface DeserializationFailureHandler<T>:
@ApplicationScoped
@Identifier("failure-retry") // Set the name of the failure handler
public class MyDeserializationFailureHandler
implements DeserializationFailureHandler<JsonObject> { // Specify the expected type
@Override
public JsonObject decorateDeserialization(Uni<JsonObject> deserialization, String topic, boolean isKey,
String deserializer, byte[] data, Headers headers) {
return deserialization
.onFailure().retry().atMost(3)
.await().atMost(Duration.ofMillis(200));
}
}Para utilizar este manipulador de falhas, o bean deve ser exposto com o qualificador @Identifier e a configuração do conector deve especificar o atributo mp.messaging.incoming.$channel.[key|value]-deserialization-failure-handler (para desserializadores de chave ou de valor).
O manipulador é chamado com detalhes da desserialização, inclusive a ação representada como Uni<T>. Na desserialização Uni podem ser implementadas estratégias de falha, como tentar novamente, fornecer um valor de reserva ou aplicar o tempo limite.
Se você não configurar um manipulador de falha de desserialização e ocorrer uma falha de desserialização, a aplicação será marcada como não saudável. Você também pode ignorar a falha, o que registrará a exceção e produzirá um valor null. Para habilitar esse comportamento, configure o atributo mp.messaging.incoming.$channel.fail-on-deserialization-failure para false.
Se o atributo fail-on-deserialization-failure estiver configurado como false e o atributo failure-strategy for dead-letter-queue, o registro com falha será enviado para o tópico da dead letter queue correspondente.
4.5. Grupos de Consumidores
No Kafka, um grupo de consumidores é um conjunto de consumidores que cooperam para consumir dados de um tópico. Um tópico é dividido em um conjunto de partições. As partições de um tópico são atribuídas entre os consumidores do grupo, o que permite dimensionar efetivamente a taxa de transferência do consumo. Observe que cada partição é atribuída a um único consumidor de um grupo. No entanto, um consumidor pode ser atribuído a várias partições se o número de partições for maior que o número de consumidores no grupo.
Vamos explorar brevemente diferentes padrões de produtor/consumidor e como implementá-los usando o Quarkus:
-
Uma única thread de consumidor dentro de um grupo de consumidores
Esse é o comportamento padrão de uma aplicação que se inscreve em um tópico do Kafka: Cada conector Kafka criará um único thread de consumidor e o colocará em um único grupo de consumidores. O ID do grupo de consumidores tem como padrão o nome da aplicação, conforme definido pela propriedade de configuração
quarkus.application.name. Ele também pode ser definido por meio da propriedadekafka.group.id.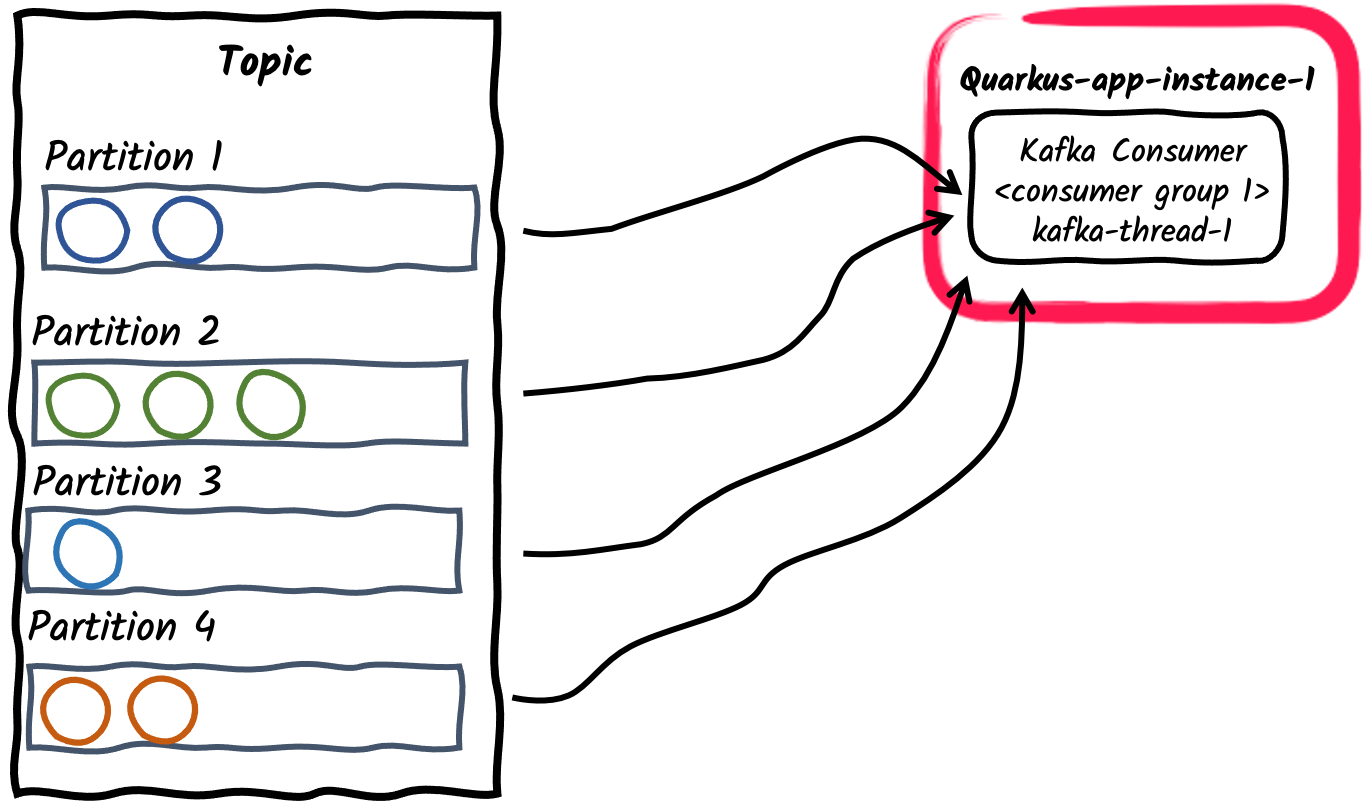
-
Vários threads de consumidores em um grupo de consumidores
Para uma determinada instância da aplicação, o número de consumidores dentro do grupo de consumidores pode ser configurado usando a propriedade mp.messaging.incoming.$channel.concurrency. As partições do tópico assinado serão divididas entre as threads de consumidores. Observe que se o valor de concorrência exceder o número de partições do tópico, algumas threads de consumidores não serão atribuídas a nenhuma partição.
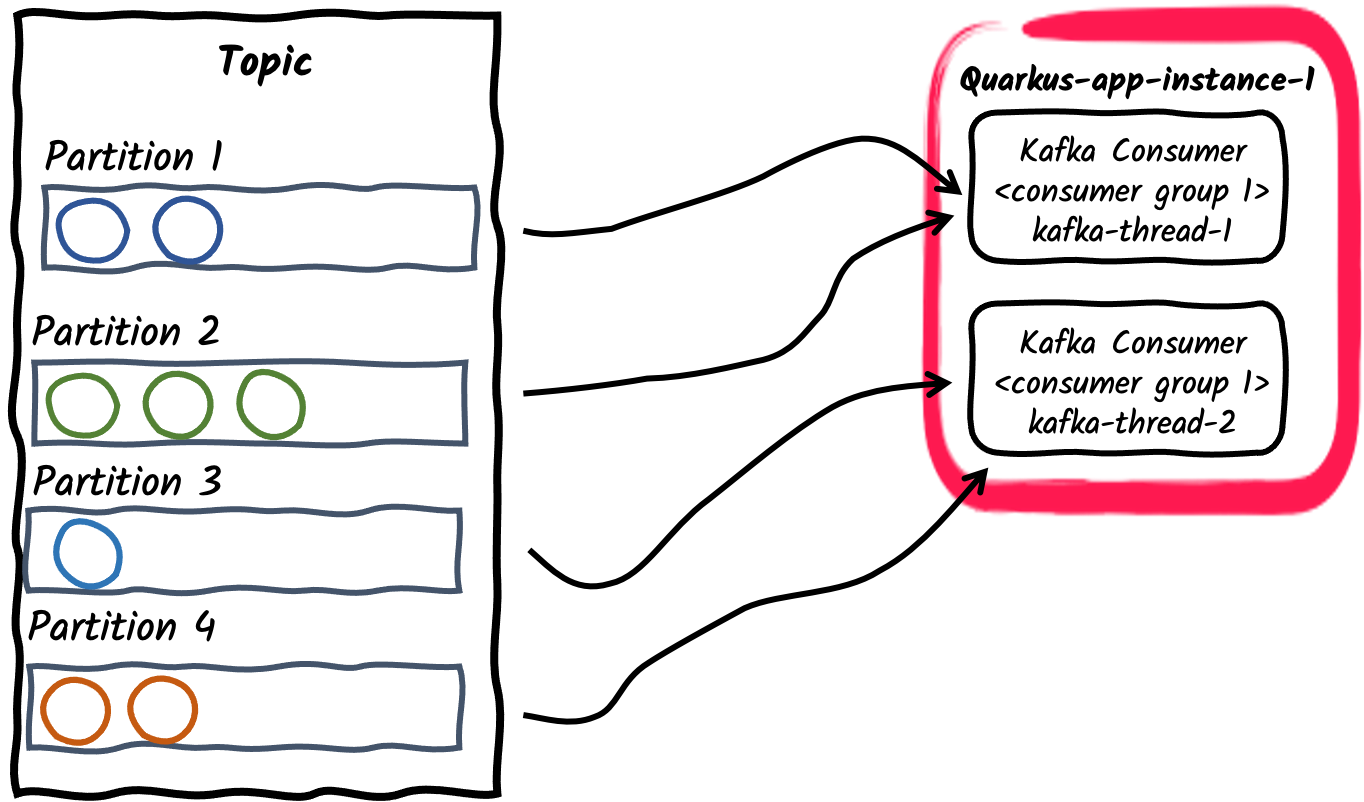 Depreciação
DepreciaçãoO atributo de concorrência fornece uma maneira agnóstica de conector para canais concorrentes não blocantes e substitui o atributo
partitionsespecífico do conector Kafka. O atributopartitionsestá, portanto, obsoleto e será removido em versões futuras. -
Várias aplicações de consumo dentro de um grupo de consumidores
Da mesma forma que no exemplo anterior, várias instâncias de uma aplicação podem se inscrever em um único grupo de consumidores, configurado por meio da propriedade
mp.messaging.incoming.$channel.group.idou deixado como padrão para o nome da aplicação. Isso, por sua vez, dividirá as partições do tópico entre as instâncias da aplicação.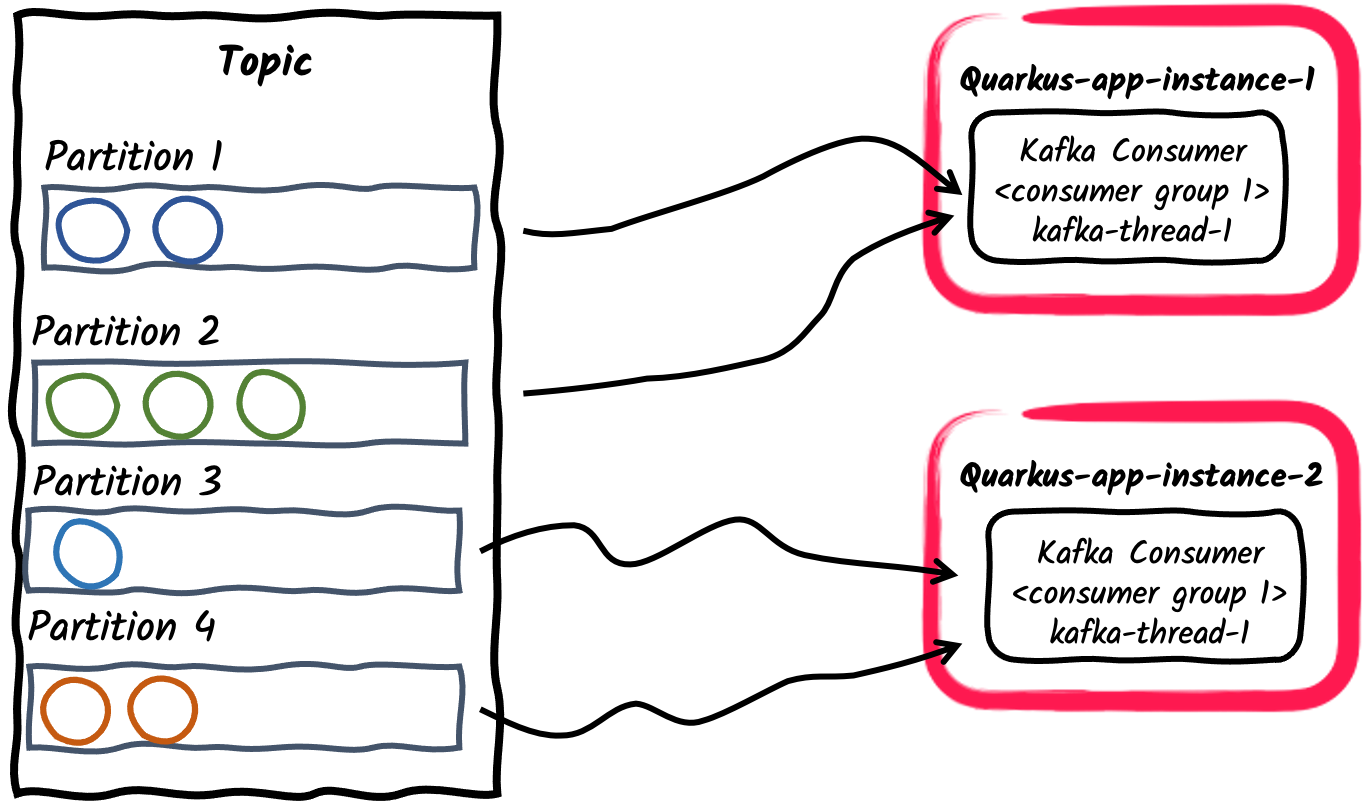
-
Pub/Sub: Vários grupos de consumidores inscritos em um tópico
Por fim, diferentes aplicações podem se inscrever independentemente nos mesmos tópicos usando diferentes IDs de grupos de consumidores. Por exemplo, as mensagens publicadas em um tópico chamado pedidos podem ser consumidas de forma independente em duas aplicações de consumo, uma com
mp.messaging.incoming.orders.group.id=invoicinge a segunda commp.messaging.incoming.orders.group.id=shipping. Assim, diferentes grupos de consumidores podem ser dimensionados de forma independente de acordo com os requisitos de consumo de mensagens.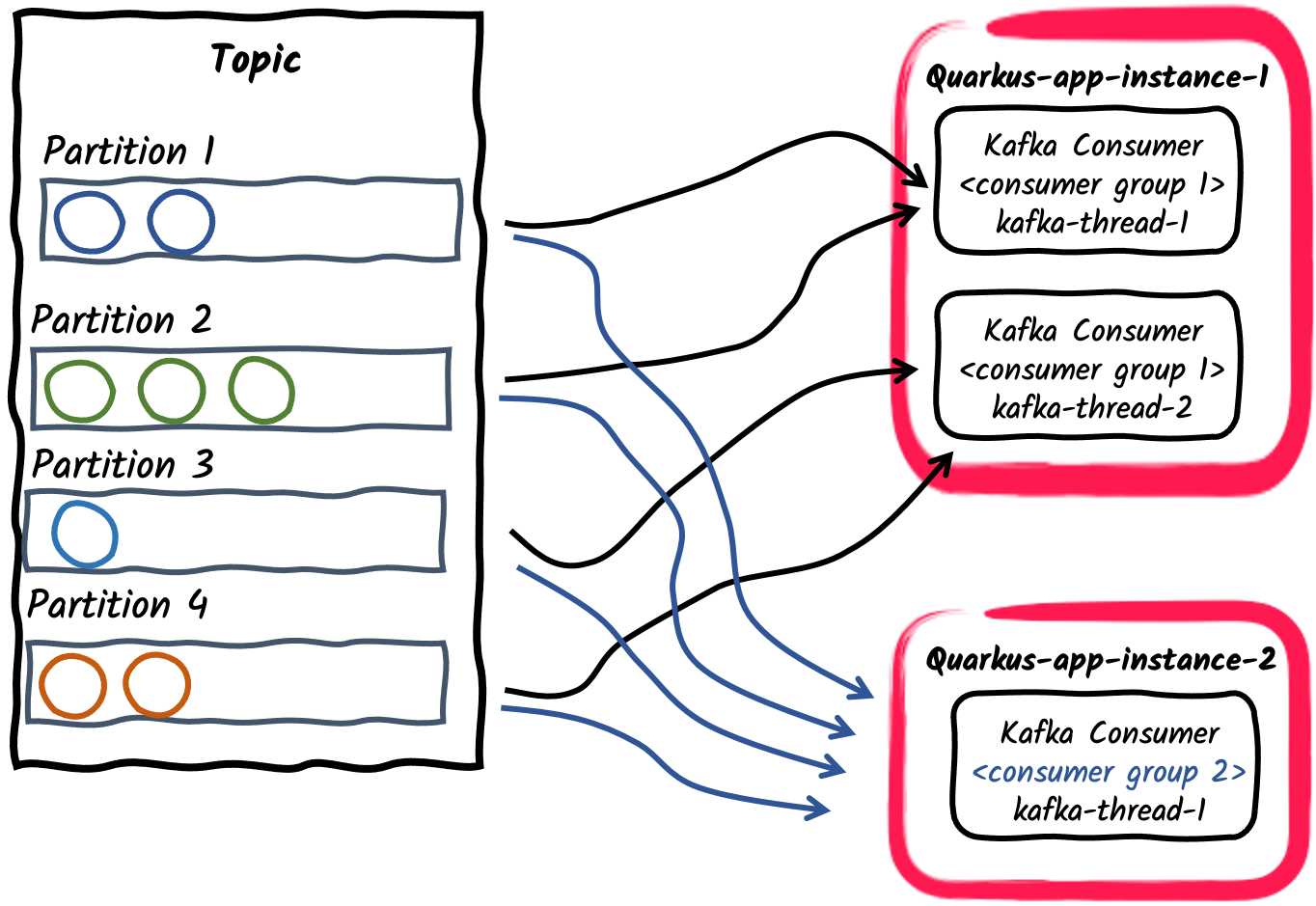
|
Um requisito negocial comum é consumir e processar os registros do Kafka em ordem. O broker Kafka preserva a ordem dos registros dentro de uma partição e não dentro de um tópico. Portanto, é importante pensar em como os registros são particionados dentro de um tópico. O particionador padrão usa o hash da chave do registro para calcular a partição de um registro ou, quando a chave não é definida, escolhe uma partição aleatoriamente por lote ou registros. Durante a operação normal, um consumidor Kafka preserva a ordem dos registros dentro de cada partição atribuída a ele.
O SmallRye Reactive Messaging mantém essa ordem para processamento, a menos que When using
Note que, devido aos rebalanceamentos dos consumidores, os consumidores Kafka apenas garantem o processamento pelo menos uma vez de registros individuais, o que significa que os registros não confirmados podem ser processados novamente pelos consumidores. |
4.5.1. Listener de Rebalanceamento do Consumidor
Em um grupo de consumidores, à medida que novos membros do grupo chegam e membros antigos saem, as partições são reatribuídas para que cada membro receba uma parte proporcional das partições. Isso é conhecido como rebalanceamento do grupo. Para lidar com a confirmação de deslocamento e as partições atribuídas, você pode fornecer um listener de rebalanceamento de consumidor. Para isso, implemente a interface io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener e exponha-a como um bean CDI com o qualificador @Idenfier. Um caso de uso comum é armazenar o deslocamento em um armazém de dados separado para implementar a semântica exatamente único ou iniciar o processamento em um deslocamento específico.
O listener é chamado sempre que a atribuição de tópico/partição do consumidor é alterada. Por exemplo, quando a aplicação é iniciada, ele invoca call-back partitionsAssigned com o conjunto inicial de tópicos/partições associados ao consumidor. Se, mais tarde, esse conjunto for alterado, ele chama novamente os callbacks partitionsRevoked e partitionsAssigned, para que você possa implementar uma lógica personalizada.
Observe que os métodos do ouvinte de rebalanceamento são chamados a partir da thread de polling do Kafka e bloquearão a thread do chamador até a conclusão. Isso ocorre porque o protocolo de rebalanceamento tem barreiras de sincronização, e o uso de código assíncrono em um ouvinte de rebalanceamento pode ser executado após a barreira de sincronização.
Quando os tópicos/partições são atribuídos ou revogados por um consumidor, o envio de mensagens é interrompido e retomado após a conclusão do rebalanceamento.
Se o ouvinte de rebalanceamento lidar com a confirmação de deslocamento em nome do usuário (usando a estratégia de confirmação NONE), o ouvinte de rebalanceamento deverá confirmar o deslocamento de forma síncrona na chamada de retorno partitionsRevoked. Também recomendamos aplicar a mesma lógica quando a aplicação for interrompida.
Ao contrário dos métodos ConsumerRebalanceListener do Apache Kafka, os métodos io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener transmitem o consumidor Kafka e o conjunto de tópicos/partições.
No exemplo a seguir, configuramos um consumidor que sempre inicia com mensagens de, no máximo, 10 minutos atrás (ou deslocamento 0). Primeiro, precisamos fornecer um bean que implemente io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener e seja anotado com io.smallrye.common.annotation.Identifier. Em seguida, devemos configurar nosso conector de entrada para usar esse bean.
package inbound;
import io.smallrye.common.annotation.Identifier;
import io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.OffsetAndTimestamp;
import org.apache.kafka.clients.consumer.TopicPartition;
import jakarta.enterprise.context.ApplicationScoped;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.logging.Logger;
@ApplicationScoped
@Identifier("rebalanced-example.rebalancer")
public class KafkaRebalancedConsumerRebalanceListener implements KafkaConsumerRebalanceListener {
private static final Logger LOGGER = Logger.getLogger(KafkaRebalancedConsumerRebalanceListener.class.getName());
/**
* When receiving a list of partitions, will search for the earliest offset within 10 minutes
* and seek the consumer to it.
*
* @param consumer underlying consumer
* @param partitions set of assigned topic partitions
*/
@Override
public void onPartitionsAssigned(Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
long now = System.currentTimeMillis();
long shouldStartAt = now - 600_000L; //10 minute ago
Map<TopicPartition, Long> request = new HashMap<>();
for (TopicPartition partition : partitions) {
LOGGER.info("Assigned " + partition);
request.put(partition, shouldStartAt);
}
Map<TopicPartition, OffsetAndTimestamp> offsets = consumer.offsetsForTimes(request);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> position : offsets.entrySet()) {
long target = position.getValue() == null ? 0L : position.getValue().offset();
LOGGER.info("Seeking position " + target + " for " + position.getKey());
consumer.seek(position.getKey(), target);
}
}
}package inbound;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.eclipse.microprofile.reactive.messaging.Acknowledgment;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Message;
import jakarta.enterprise.context.ApplicationScoped;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.CompletionStage;
@ApplicationScoped
public class KafkaRebalancedConsumer {
@Incoming("rebalanced-example")
@Acknowledgment(Acknowledgment.Strategy.NONE)
public CompletionStage<Void> consume(Message<ConsumerRecord<Integer, String>> message) {
// We don't need to ACK messages because in this example,
// we set offset during consumer rebalance
return CompletableFuture.completedFuture(null);
}
}Para configurar o conector de entrada para usar o ouvinte fornecido, definimos o identificador do ouvinte de rebalanceamento do consumidor: mp.messaging.incoming.rebalanced-example.consumer-rebalance-listener.name=rebalanced-example.rebalancer
Ou fazer com que o nome do ouvinte seja o mesmo que o ID do grupo:
mp.messaging.incoming.rebalanced-example.group.id=rebalanced-example.rebalancer
A definição do nome do ouvinte de rebalanceamento do consumidor tem precedência sobre a utilização do ID do grupo.
4.5.2. Utilizando grupos de consumidores únicos
Para processar todos os registros de um tópico (desde o seu início), é necessário:
-
definir
auto.deslocamento.reset = earliest -
atribuir o seu consumidor a um grupo de consumidores não utilizado por nenhuma outra aplicação.
O Quarkus gera um UUID que muda entre duas execuções (inclusive no modo de desenvolvimento). Assim, você tem certeza de que nenhum outro consumidor o utiliza e recebe um novo ID de grupo exclusivo sempre que a aplicação é iniciada.
Você pode utilizar esse UUID gerado como o grupo de consumidores da seguinte forma:
mp.messaging.incoming.your-channel.auto.offset.reset=earliest
mp.messaging.incoming.your-channel.group.id=${quarkus.uuid}
Se o atributo group.id não estiver definido, a propriedade de configuração quarkus.application.name é utilizada por padrão.
|
4.5.3. Atribuição manual de tópico-partição
O atributo de canal assign-seek permite atribuir manualmente tópico-partição a um canal de entrada do Kafka, e, opcionalmente, buscar um deslocamento especificado na partição para começar a consumir registros. Se assign-seek for usado, o consumidor não será inscrito dinamicamente nos tópicos, mas, em vez disso, atribuirá estaticamente as partições descritas. No tópico-partição manual o rebalanceamento não ocorre e, portanto, os ouvintes de rebalanceamento nunca são chamados.
O atributo recebe uma lista de triplas separadas por vírgulas: <topic>:<partition>:<deslocamento>.
Por exemplo, a configuração
mp.messaging.incoming.data.assign-seek=topic1:0:10, topic2:1:20atribui o consumidor à:
-
Partição 0 do tópico 'topic', configurando a posição inicial no deslocamento 10.
-
Partição 1 do tópico 'topic2', configurando a posição inicial no deslocamento 20.
O tópico, partição, e deslocamento em cada tripla pode ter as seguintes variações:
-
Se o tópico for omitido, o tópico configurado será usado.
-
Se o deslocamento for omitido, partições são atribuídas para o consumidor mas não serão buscadas para o deslocamento.
-
Se o deslocamento é 0, ele busca o início do tópico-partição.
-
Se o deslocamento é -1, ele busca o fim do tópico-partição.
4.6. Recebendo Registros Kafka em Lotes
Por padrão, os métodos de entrada recebem cada registro do Kafka individualmente. Por trás disso, os clientes consumidores do Kafka consultam o broker constantemente e recebem registros em lotes, apresentados dentro do contêiner ConsumerRecords.
No modo batch, a sua aplicação pode receber todos os registros devolvidos pela consulta do consumidor de uma só vez.
Para tal, é necessário especificar um tipo de contêiner compatível para receber todos os dados:
@Incoming("prices")
public void consume(List<Double> prices) {
for (double price : prices) {
// process price
}
}O método incoming também pode receber os tipos Message<List<Payload>>, Message<ConsumerRecords<Key, Payload>> e ConsumerRecords<Key, Payload>. Eles fornecem acesso aos detalhes do registro, como offset ou timestamp:
@Incoming("prices")
public CompletionStage<Void> consumeMessage(Message<ConsumerRecords<String, Double>> records) {
for (ConsumerRecord<String, Double> record : records.getPayload()) {
String payload = record.getPayload();
String topic = record.getTopic();
// process messages
}
// ack will commit the latest offsets (per partition) of the batch.
return records.ack();
}Observe que o processamento bem-sucedido do lote de registros de entrada confirmará os deslocamentos mais recentes de cada partição recebida dentro do lote. A estratégia de confirmação configurada será aplicada somente a esses registros.
Inversamente, se o processamento lançar uma exceção, todas as mensagens são não reconhecidas, aplicando a estratégia de falha a todos os registros dentro do lote.
|
O Quarkus detecta automaticamente os tipos de lote para os canais de entrada e define a configuração do lote automaticamente. Você pode configurar o modo de lote explicitamente com a propriedade |
4.7. Share Groups (Kafka Queues)
|
Kafka Share Groups require Apache Kafka 4.2+ brokers and are an early access feature in Kafka. |
Share Groups (KIP-932) provide a queue-like consumption model for Kafka topics. Unlike consumer groups, records are distributed across share consumers without explicit partition assignment — the broker handles distribution of records and acquisition locks automatically. This provides queue-style workloads where records are processed by any available consumer with at-least-once delivery semantics.
4.7.1. Enabling Share Groups
To enable share group consumption, set the share-group attribute on the incoming channel:
mp.messaging.incoming.queue.connector=smallrye-kafka
mp.messaging.incoming.queue.topic=prices
mp.messaging.incoming.queue.value.deserializer=org.apache.kafka.common.serialization.DoubleDeserializer
mp.messaging.incoming.queue.share-group=trueConsuming messages works like any other incoming channel:
@ApplicationScoped
public class KafkaShareGroupConsumer {
@Incoming("queue")
public void consume(double price) {
// process price
}
}4.7.2. Per-record Acknowledgement
Share groups support three acknowledgement types:
-
ACCEPT: Record processed successfully (default on ack).
-
RELEASE: Record failed processing and is eligible for re-delivery to another consumer.
-
REJECT: Permanent rejection with no re-delivery.
You can control the acknowledgement per record using ShareGroupAcknowledgement metadata:
@Incoming("queue")
@Outgoing("processed")
public String consume(double msg, ShareGroupAcknowledgement ack) {
try {
// successful processing is ACCEPT
return process(msg);
} catch (TransientException e) {
ack.release();
} catch (Exception e) {
ack.reject();
}
// Skip publishing message
return null;
}4.7.3. Acquisition Lock Renewal
Each acquired record has a time-limited acquisition lock managed by the broker.
The connector tracks in-processing records and periodically renews their locks to prevent re-delivery.
The share-group.unprocessed-record-max-age.ms attribute controls this behavior:
mp.messaging.incoming.queue.share-group=true
mp.messaging.incoming.queue.share-group.unprocessed-record-max-age.ms=30000When enabled (default: 60000), records still in processing are periodically renewed with the broker.
If a record exceeds this timeout, the health check reports a failure.
Set to 0 to disable monitoring and automatic renewal.
4.7.4. Batch Mode
Share groups support batch consumption.
Enable it by setting batch=true alongside share-group=true:
mp.messaging.incoming.queue.share-group=true
mp.messaging.incoming.queue.batch=trueWith per-record acknowledgement control, each record inside a batch can be individually acknowledged using IncomingKafkaRecordBatchMetadata:
@Incoming("queue")
public void consume(ConsumerRecords<String, String> batch, IncomingKafkaRecordBatchMetadata metadata) {
for (var record : batch) {
ShareGroupAcknowledgement ack = metadata.getMetadataForRecord(record, ShareGroupAcknowledgement.class);
String event = record.value();
if (event.startsWith("INVALID")) {
Log.warnf("[Batch] Rejecting invalid event: %s", event);
ack.reject();
} else {
Log.infof("[Batch] Accepted event: %s", event);
ack.accept();
}
}
}4.8. Processamento com estado com Ponto de Verificação
|
A estratégia de submissão |
A estratégia de confirmação do SmallRye Reactive Messaging checkpoint permite que os aplicativos do consumidor processem as mensagens de uma forma com estado, respeitando também a escalabilidade do consumidor Kafka.
Um canal de entrada com a estratégia de confirmação checkpoint persiste os offsets do consumidor em um state store externo, como um banco de dados relacional ou um armazenamento de valor-chave.
Como resultado do processamento dos registros consumidos, o aplicativo do consumidor pode acumular um estado interno para cada partição de tópico atribuída ao consumidor Kafka.
Esse estado local será periodicamente mantido no armazenamento de estado e será associado ao deslocamento do registro que o produziu.
Essa estratégia não confirma nenhum deslocamento para o broker Kafka, portanto, quando novas partições são atribuídas ao consumidor, ou seja, o consumidor é reiniciado ou as instâncias do grupo de consumidores são escalonadas, o consumidor retoma o processamento a partir do último deslocamento do ponto de verificação com seu estado salvo.
O código do consumidor do canal @Incoming pode manipular o estado de processamento por meio da API CheckpointMetadata. Por exemplo, um consumidor que calcula a média móvel dos preços recebidos em um tópico do Kafka teria a seguinte aparência:
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Message;
import io.smallrye.reactive.messaging.kafka.KafkaRecord;
import io.smallrye.reactive.messaging.kafka.commit.CheckpointMetadata;
@ApplicationScoped
public class MeanCheckpointConsumer {
@Incoming("prices")
public CompletionStage<Void> consume(Message<Double> record) {
// Get the `CheckpointMetadata` from the incoming message
CheckpointMetadata<AveragePrice> checkpoint = CheckpointMetadata.fromMessage(record);
// `CheckpointMetadata` allows transforming the processing state
// Applies the given function, starting from the value `0.0` when no previous state exists
checkpoint.transform(new AveragePrice(), average -> average.update(record.getPayload()), /* persistOnAck */ true);
// `persistOnAck` flag set to true, ack will persist the processing state
// associated with the latest offset (per partition).
return record.ack();
}
static class AveragePrice {
long count;
double mean;
AveragePrice update(double newPrice) {
mean += ((newPrice - mean) / ++count);
return this;
}
}
}O método transform aplica a função de transformação ao estado atual, produzindo um estado alterado e registrando-o localmente para checkpointing. Por padrão, o estado local é mantido no armazém de estado periodicamente, período especificado por auto.commit.interval.ms, (padrão: 5000). Se o sinalizador persistOnAck for fornecido, o estado mais recente será persistido no armazém de estado ansiosamente no reconhecimento da mensagem. O método setNext funciona de forma semelhante, definindo diretamente o estado mais recente.
A estratégia de confirmação de ponto de verificação rastreia quando um estado de processamento foi mantido pela última vez para cada partição de tópico. Se uma alteração de estado pendente não puder ser mantida por checkpoint.unsynced-state-max-age.ms (padrão: 10000), o canal será marcado como não saudável.
4.8.1. State stores (armazéns de estado)
As implementações de armazém de estado determinam onde e como os estados de processamento são mantidos. Isso é configurado pela propriedade mp.messaging.incoming.[channel-name].checkpoint.state-store. A serialização de objetos de estado depende da implementação do armazém de estado. Para instruir os armazéns de estado para serialização, pode ser necessário configurar o nome da classe dos objetos de estado usando a propriedade mp.messaging.incoming.[channel-name].checkpoint.state-type.
O Quarkus fornece as seguintes implementações de armazém de estado:
-
quarkus-redis: Usa a extensãoquarkus-redis-clientpara manter os estados de processamento. Jackson é usado para serializar o estado de processamento em Json. Para objetos complexos, é necessário configurar a propriedadecheckpoint.state-typecom o nome da classe do objeto. Por padrão, o armazém de estado usa o cliente Redis padrão, mas se for necessário usar um cliente nomeado, o nome do cliente poderá ser especificado usando a propriedademp.messaging.incoming.[channel-name].checkpoint.quarkus-redis.client-name. Os estados de processamento serão armazenados no Redis usando o esquema de nomeação de chave[consumer-group-id]:[topic]:[partition].
Por exemplo, a configuração do código anterior seria a seguinte:
mp.messaging.incoming.prices.group.id=prices-checkpoint
# ...
mp.messaging.incoming.prices.commit-strategy=checkpoint
mp.messaging.incoming.prices.checkpoint.state-store=quarkus-redis
mp.messaging.incoming.prices.checkpoint.state-type=org.acme.MeanCheckpointConsumer.AveragePrice
# ...
# if using a named redis client
mp.messaging.incoming.prices.checkpoint.quarkus-redis.client-name=my-redis
quarkus.redis.my-redis.hosts=redis://localhost:7000
quarkus.redis.my-redis.password=<redis-pwd>-
quarkus-hibernate-reactive: Usa a extensão quarkus-hibernate-reactive para manter os estados de processamento. Os objetos de estado de processamento devem ser uma entidade da Jakarta Persistence e estender a classeCheckpointEntity, que lida com identificadores de objeto compostos pelo ID do grupo de consumidores, tópico e partição. Portanto, o nome da classe da entidade precisa ser configurado usando a propriedadecheckpoint.state-type.
Por exemplo, a configuração do código anterior seria a seguinte:
mp.messaging.incoming.prices.group.id=prices-checkpoint
# ...
mp.messaging.incoming.prices.commit-strategy=checkpoint
mp.messaging.incoming.prices.checkpoint.state-store=quarkus-hibernate-reactive
mp.messaging.incoming.prices.checkpoint.state-type=org.acme.AveragePriceEntitySendo AveragePriceEntity uma entidade da Jakarta Persistence que estende CheckpointEntity:
package org.acme;
import jakarta.persistence.Entity;
import io.quarkus.smallrye.reactivemessaging.kafka.CheckpointEntity;
@Entity
public class AveragePriceEntity extends CheckpointEntity {
public long count;
public double mean;
public AveragePriceEntity update(double newPrice) {
mean += ((newPrice - mean) / ++count);
return this;
}
}-
quarkus-hibernate-orm: Usa a extensão quarkus-hibernate-orm para manter os estados de processamento. É semelhante ao armazém de estado anterior, mas usa o Hibernate ORM em vez do Hibernate Reativo.
Quando configurado, ele pode usar um persistence-unit nomeado para o armazém de estado de ponto de verificação:
mp.messaging.incoming.prices.commit-strategy=checkpoint
mp.messaging.incoming.prices.checkpoint.state-store=quarkus-hibernate-orm
mp.messaging.incoming.prices.checkpoint.state-type=org.acme.AveragePriceEntity
mp.messaging.incoming.prices.checkpoint.quarkus-hibernate-orm.persistence-unit=prices
# ... Setup "prices" persistence unit
quarkus.datasource."prices".db-kind=postgresql
quarkus.datasource."prices".username=<your username>
quarkus.datasource."prices".password=<your password>
quarkus.datasource."prices".jdbc.url=jdbc:postgresql://localhost:5432/hibernate_orm_test
quarkus.hibernate-orm."prices".datasource=prices
quarkus.hibernate-orm."prices".packages=org.acmePara obter instruções sobre como implementar armazéns de estado personalizados, consulte Implementando Armazéns de Estado.
5. Enviando mensagens para o Kafka
A configuração dos canais de saída do conector Kafka é semelhante à dos canais de entrada:
%prod.kafka.bootstrap.servers=kafka:9092 (1)
mp.messaging.outgoing.prices-out.connector=smallrye-kafka (2)
mp.messaging.outgoing.prices-out.topic=prices (3)| 1 | Configure a localização do broker para o perfil de produção. Você pode configurá-lo globalmente ou por canal usando a propriedade mp.messaging.outgoing.$channel.bootstrap.servers. No modo de desenvolvimento e ao executar testes, Dev Services para o Kafka inicia automaticamente um broker Kafka. Quando não fornecida, esta propriedade tem o valor padrão localhost:9092. |
| 2 | Configure o conector para gerenciar o canal prices-out. |
| 3 | Por padrão, o nome do tópico é igual ao nome do canal. Você pode configurar o atributo de tópico para o substituir. |
|
Dentro da configuração da aplicação, os nomes dos canais são exclusivos. Portanto, se quiser configurar um canal de entrada e de saída no mesmo tópico, você precisará nomear os canais de forma diferente (como nos exemplos deste guia, |
Em seguida, sua aplicação pode gerar mensagens e publicá-las no canal prices-out. Ele pode usar os conteúdos do double, como no trecho a seguir:
import io.smallrye.mutiny.Multi;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import jakarta.enterprise.context.ApplicationScoped;
import java.time.Duration;
import java.util.Random;
@ApplicationScoped
public class KafkaPriceProducer {
private final Random random = new Random();
@Outgoing("prices-out")
public Multi<Double> generate() {
// Build an infinite stream of random prices
// It emits a price every second
return Multi.createFrom().ticks().every(Duration.ofSeconds(1))
.map(x -> random.nextDouble());
}
}|
Você não deve chamar métodos anotados com |
Observe que o método generate retorna um Multi<Double>, que implementa a interface Publisher do Reactive Streams. Esse publicador será usado pela estrutura para gerar mensagens e enviá-las ao tópico Kafka configurado.
Em vez de devolver uma conteúdo, você pode devolver um io.smallrye.reactive.messaging.kafka.Record para enviar pares de chave/valor:
@Outgoing("out")
public Multi<Record<String, Double>> generate() {
return Multi.createFrom().ticks().every(Duration.ofSeconds(1))
.map(x -> Record.of("my-key", random.nextDouble()));
}O conteúdo pode ser envolvido em uma org.eclipse.microprofile.reactive.messaging.Message para ter mais controle sobre os registros escritos:
@Outgoing("generated-price")
public Multi<Message<Double>> generate() {
return Multi.createFrom().ticks().every(Duration.ofSeconds(1))
.map(x -> Message.of(random.nextDouble())
.addMetadata(OutgoingKafkaRecordMetadata.<String>builder()
.withKey("my-key")
.withTopic("my-key-prices")
.withHeaders(new RecordHeaders().add("my-header", "value".getBytes()))
.build()));
}OutgoingKafkaRecordMetadata permite definir atributos de metadados do registro do Kafka, como key, topic, partition ou timestamp. Um caso de uso é selecionar dinamicamente o tópico de destino de uma mensagem. Nesse caso, em vez de configurar o tópico dentro do arquivo de configuração da aplicação, você precisa usar os metadados de saída para definir o nome do tópico.
Além das assinaturas de método que retornam um Publisher do Reactive Stream (Multi é uma implementação de Publisher), o método de saída também pode retornar uma única mensagem. Nesse caso, o produtor usará esse método como gerador para criar um fluxo infinito.
@Outgoing("prices-out") T generate(); // T excluding void
@Outgoing("prices-out") Message<T> generate();
@Outgoing("prices-out") Uni<T> generate();
@Outgoing("prices-out") Uni<Message<T>> generate();
@Outgoing("prices-out") CompletionStage<T> generate();
@Outgoing("prices-out") CompletionStage<Message<T>> generate();5.1. Enviando de mensagens com o Emitter
Às vezes, você precisa ter uma forma imperativa de enviar mensagens.
Por exemplo, se você precisar enviar uma mensagem para um fluxo ao receber uma solicitação POST dentro de um endpoint REST. Nesse caso, você não pode usar @Outgoing porque seu método tem parâmetros.
Para tal, pode utilizar um Emitter.
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
import jakarta.inject.Inject;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.core.MediaType;
@Path("/prices")
public class PriceResource {
@Inject
@Channel("price-create")
Emitter<Double> priceEmitter;
@POST
@Consumes(MediaType.TEXT_PLAIN)
public void addPrice(Double price) {
CompletionStage<Void> ack = priceEmitter.send(price);
}
}O envio de um conteúdo devolve um CompletionStage, concluído quando a mensagem é recebida. Se a transmissão da mensagem falhar, o CompletionStage é completado excepcionalmente com a razão do não reconhecimento.
|
A configuração de |
|
Usando o |
Com a API Emitter, você também pode encapsular o payload de saída dentro de Message<T>. Tal como nos exemplos anteriores, Message te permite tratar os casos de reconhecimento/não reconhecimento de forma diferente.
import java.util.concurrent.CompletableFuture;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
import jakarta.inject.Inject;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.core.MediaType;
@Path("/prices")
public class PriceResource {
@Inject @Channel("price-create") Emitter<Double> priceEmitter;
@POST
@Consumes(MediaType.TEXT_PLAIN)
public void addPrice(Double price) {
priceEmitter.send(Message.of(price)
.withAck(() -> {
// Called when the message is acked
return CompletableFuture.completedFuture(null);
})
.withNack(throwable -> {
// Called when the message is nacked
return CompletableFuture.completedFuture(null);
}));
}
}Se preferir usar APIs de fluxo reativo, você pode usar MutinyEmitter que retornará Uni<Void> do método send. Portanto, você pode usar as APIs do Mutiny para lidar com mensagens e erros downstream.
import org.eclipse.microprofile.reactive.messaging.Channel;
import jakarta.inject.Inject;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.core.MediaType;
import io.smallrye.reactive.messaging.MutinyEmitter;
@Path("/prices")
public class PriceResource {
@Inject
@Channel("price-create")
MutinyEmitter<Double> priceEmitter;
@POST
@Consumes(MediaType.TEXT_PLAIN)
public Uni<String> addPrice(Double price) {
return quoteRequestEmitter.send(price)
.map(x -> "ok")
.onFailure().recoverWithItem("ko");
}
}Também é possível bloquear o envio do evento para o emissor com o método sendAndAwait. Ele só retornará do método quando o evento for aceito ou bloqueado pelo receptor.
|
Depreciação
As classes
O novo método |
|
Depreciação
|
Mais informações sobre como usar Emitter podem ser encontradas em Mensageria Reativa do SmallRye - Emissores e Canais
5.2. Escrever Reconhecimento
Quando o broker do Kafka recebe um registro, seu reconhecimento pode demorar, dependendo da configuração. Além disso, ele armazena na memória os registros que não podem ser gravados.
Por padrão, o conector espera que o Kafka confirme o registro para continuar o processamento (reconhecendo a mensagem recebida). Você pode desativar isso definindo o atributo waitForWriteCompletion como false.
Note que o atributo acks tem um enorme impacto no reconhecimento do registro.
Se não for possível escrever um registro, a mensagem é não reconhecida.
5.3. Contrapressão
O conector de saída do Kafka lida com a contrapressão, monitorando o número de mensagens em trânsito que aguardam gravação no broker do Kafka. O número de mensagens em trânsito é configurado usando o atributo max-inflight-messages e o padrão é 1024.
O conector envia apenas essa quantidade de mensagens ao mesmo tempo. Nenhuma outra mensagem será enviada até que pelo menos uma mensagem em andamento seja confirmada pelo broker. Em seguida, o conector grava uma nova mensagem no Kafka quando uma das mensagens em andamento do broker é reconhecida. Certifique-se de configurar o batch.size e o linger.ms do Kafka adequadamente.
Você também pode remover o limite de mensagens em andamento definindo max-inflight-messages como 0. No entanto, observe que o produtor do Kafka poderá bloquear se o número de solicitações atingir max.in.flight.requests.per.connection.
5.4. Nova tentativa de envio de mensagens
Quando o produtor Kafka recebe um erro do servidor, se for um erro transitório e recuperável, o cliente tentará enviar novamente o lote de mensagens. Esse comportamento é controlado pelos parâmetros retries e retry.backoff.ms. Além disso, a Mensageria Reativa do SmallRye tentará enviar novamente mensagens individuais em erros recuperáveis, dependendo dos parâmetros retries e delivery.timeout.ms.
Observe que, embora ter novas tentativas em um sistema confiável seja uma prática recomendada, o parâmetro max.in.flight.requests.per.connection tem como padrão 5, o que significa que a ordem das mensagens não é garantida. Se a ordem das mensagens for imprescindível para o seu caso de uso, definir max.in.flight.requests.per.connection como 1 garantirá que um único lote de mensagens seja enviado por vez, às custas de limitar a taxa de transferência do produtor.
Para aplicar um mecanismo de retentativa em erros de processamento, consulte a seção sobre Repetindo o processamento.
5.5. Tratando Falhas de Serialização
Para o cliente produtor do Kafka, as falhas de serialização não são recuperáveis e, portanto, o envio da mensagem não é repetido. Nesses casos, talvez seja necessário aplicar uma estratégia de falha para o serializador. Para isso, você precisa criar um bean que implemente a interface SerializationFailureHandler<T>:
@ApplicationScoped
@Identifier("failure-fallback") // Set the name of the failure handler
public class MySerializationFailureHandler
implements SerializationFailureHandler<JsonObject> { // Specify the expected type
@Override
public byte[] decorateSerialization(Uni<byte[]> serialization, String topic, boolean isKey,
String serializer, Object data, Headers headers) {
return serialization
.onFailure().retry().atMost(3)
.await().indefinitely();
}
}Para utilizar este manipulador de falhas, o bean deve ser exposto com o qualificador @Identifier e a configuração do conector deve especificar o atributo mp.messaging.outgoing.$channel.[key|value]-serialization-failure-handler (para serializadores de chave ou de valor).
O manipulador é chamado com detalhes da serialização, incluindo a ação representada como Uni<byte[]>. Observe que o método deve aguardar o resultado e retornar o vetor de bytes serializado.
5.6. Canais na memória
Em alguns casos de uso, é conveniente usar os padrões de mensagens para transferir mensagens dentro da mesma aplicação. Quando você não conecta um canal a um backend de mensagens como o Kafka, tudo acontece na memória, e os fluxos são criados encadeando métodos. Cada cadeia ainda é um fluxo reativo e aplica o protocolo de contrapressão.
A estrutura verifica se a cadeia produtor/consumidor está completa, o que significa que, se a aplicação gravar mensagens em um canal na memória (usando um método com apenas @Outgoing, ou um Emitter), ele também deverá consumir as mensagens de dentro da aplicação (usando um método com apenas @Incoming ou usando um fluxo não gerenciado).
5.7. Difusão de mensagens em vários consumidores
Por padrão, um canal pode ser vinculado a um único consumidor, usando o método @Incoming ou o fluxo reativo @Channel. Na inicialização da aplicação, os canais são verificados para formar uma cadeia de consumidores e produtores com um único consumidor e produtor. Você pode substituir esse comportamento definindo mp.messaging.$channel.broadcast=true em um canal.
No caso dos canais na memória, a anotação @Broadcast pode ser utilizada no método @Outgoing. Por exemplo,
import java.util.Random;
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import io.smallrye.reactive.messaging.annotations.Broadcast;
@ApplicationScoped
public class MultipleConsumer {
private final Random random = new Random();
@Outgoing("in-memory-channel")
@Broadcast
double generate() {
return random.nextDouble();
}
@Incoming("in-memory-channel")
void consumeAndLog(double price) {
System.out.println(price);
}
@Incoming("in-memory-channel")
@Outgoing("prices2")
double consumeAndSend(double price) {
return price;
}
}|
Reciprocamente, vários produtores no mesmo canal podem ser mesclados com a configuração |
A repetição da anotação @Outgoing nos métodos de saída ou de processamento permite outra maneira de enviar mensagens para vários canais de saída:
import java.util.Random;
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
@ApplicationScoped
public class MultipleProducers {
private final Random random = new Random();
@Outgoing("generated")
@Outgoing("generated-2")
double priceBroadcast() {
return random.nextDouble();
}
}No exemplo anterior, o preço gerado será transmitido para ambos os canais de saída. O exemplo a seguir envia seletivamente mensagens para vários canais de saída usando o objeto de contêiner Targeted, contendo key como nome do canal e value como conteúdo da mensagem.
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import io.smallrye.reactive.messaging.Targeted;
@ApplicationScoped
public class TargetedProducers {
@Incoming("in")
@Outgoing("out1")
@Outgoing("out2")
@Outgoing("out3")
public Targeted process(double price) {
Targeted targeted = Targeted.of("out1", "Price: " + price,
"out2", "Quote: " + price);
if (price > 90.0) {
return targeted.with("out3", price);
}
return targeted;
}
}Observe que a detecção automática para serializadores do Kafka não funciona para assinaturas usando o Targeted.
Informações detalhadas sobre a utilização da anotação @Blocking podem ser encontradas em Mensageria Reativa do SmallRye - Lindando com execução blocante.
5.8. Transações Kafka
As transações do Kafka permitem gravações atômicas em vários tópicos e partições do Kafka. O conector Kafka fornece o emissor personalizado KafkaTransactions para gravar registros do Kafka dentro de uma transação. Ele pode ser injetado como um emissor regular @Channel:
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.KafkaRecord;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@ApplicationScoped
public class KafkaTransactionalProducer {
@Channel("tx-out-example")
KafkaTransactions<String> txProducer;
public Uni<Void> emitInTransaction() {
return txProducer.withTransaction(emitter -> {
emitter.send(KafkaRecord.of(1, "a"));
emitter.send(KafkaRecord.of(2, "b"));
emitter.send(KafkaRecord.of(3, "c"));
return Uni.createFrom().voidItem();
});
}
}A função dada ao método withTransaction recebe um TransactionalEmitter para produzir registros e devolve um Uni que fornece o resultado da transação.
-
Se o processamento for concluído com êxito, o produtor é descarregado e a transação é confirmada.
-
Se o processamento lançar uma exceção, retornar uma
Unide falha, ou marcar oTransactionalEmitterpara abortar, a transação é abortada.
Os produtores transacionais do Kafka exigem a configuração da propriedade do cliente acks=all e um ID exclusivo para transactional.id, o que implica enable.idempotence=true. Quando o Quarkus detecta o uso de KafkaTransactions para um canal de saída, ele configura essas propriedades no canal, fornecendo um valor padrão de "${quarkus.application.name}-${channelName}" para a propriedade transactional.id.
Note que, para utilização em produção, o transactional.id deve ser único em todas as instâncias da aplicação.
|
By default, a Observe que, na Mensageria Reativa, a execução dos métodos de processamento já é serializada, a menos que Um exemplo de uso pode ser encontrado em Encadeando Transações do Kafka com transações Reativas do Hibernate. |
5.8.1. Concurrent Exactly-Once Processing with Pooled Producers
By default, KafkaTransactions uses a single producer, so only one transaction can run at a time.
The pooled producer mode uses a pool of Kafka producers, each with its own transactional.id, derived from the configured transactional.id (e.g., my-tx-id-1, my-tx-id-2, etc.).
Each transaction reserves a producer from the pool for the duration of the transaction, enabling concurrent exactly-once processing.
Combined with @Blocking(ordered = false) and ordered=partition on the incoming channel, records from different partitions can be processed concurrently while maintaining per-partition ordering:
mp.messaging.incoming.prices-in.ordered=partition
mp.messaging.incoming.prices-in.commit-strategy=ignore
mp.messaging.incoming.prices-in.failure-strategy=ignore
mp.messaging.outgoing.prices-out.pooled-producer=true
// when running on dev mode with Kafka Dev Services, pre-create 3 producers for the 3 partitions
quarkus.kafka.devservices.topic-partitions.prices-in=3
quarkus.kafka.devservices.topic-partitions.prices-out=3The KafkaTransactions API is the same as for regular exactly-once processing.
The outgoing record’s partition defaults to the incoming record’s partition:
import jakarta.enterprise.context.ApplicationScoped;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.OnOverflow;
import io.quarkus.logging.Log;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.annotations.Blocking;
import io.smallrye.reactive.messaging.kafka.KafkaRecord;
import io.smallrye.reactive.messaging.kafka.api.IncomingKafkaRecordMetadata;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@ApplicationScoped
public class ConcurrentExactlyOnceProcessor {
@Channel("prices-out")
@OnOverflow(value = OnOverflow.Strategy.BUFFER, bufferSize = 500)
KafkaTransactions<Integer> txProducer;
@Incoming("prices-in")
@Blocking(ordered = false)
public void process(ConsumerRecord<String, Integer> record, (1)
IncomingKafkaRecordMetadata<String, Integer> metadata) {
txProducer.withTransactionAndAwait(metadata, emitter -> { (2)
emitter.send(KafkaRecord.of(record.key(), record.value() + 1));
return Uni.createFrom().voidItem();
});
}
}| 1 | @Blocking(ordered = false) enables concurrent processing across worker threads. With ordered=partition, records from the same partition are still processed sequentially. The record payload and metadata are injected directly as method parameters. |
| 2 | withTransactionAndAwait is the synchronous variant that blocks the worker thread until the transaction completes. It accepts IncomingKafkaRecordMetadata for managing consumer offset commits within the transaction. Each call acquires a separate producer from the pool. |
Producers are returned to the pool after commit or abort.
On abort, only the partitions involved in that transaction are reset so other concurrent transactions are not affected.
By default, the pool grows lazily to match actual concurrency, up to pooled-producer.max-pool-size (default 10).
Number of producers that are pre-created at startup can be configured with pooled-producer.initial-pool-size (default 0).
6. Requisição-Resposta do Kafka
O padrão de Requisição-Resposta do Kafka permite publicar um registro de requisição em um tópico do Kafka e, em seguida, aguardar um registro de resposta que responda à requisição inicial. O conector Kafka fornece o emissor personalizado KafkaRequestReply, que implementa o solicitante (ou cliente) do padrão de requisição-resposta para canais de saída do Kafka:
Ele pode ser injetado como um emissor @Channel regular:
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.reply.KafkaRequestReply;
@ApplicationScoped
@Path("/kafka")
public class KafkaRequestReplyEmitter {
@Channel("request-reply")
KafkaRequestReply<Integer, String> requestReply;
@POST
@Path("/req-rep")
@Produces(MediaType.TEXT_PLAIN)
public Uni<String> post(Integer request) {
return requestReply.request(request);
}
}O método de requisição publica o registro no tópico de destino configurado do canal de saída e consulta um tópico de resposta (por padrão, o tópico de destino com o sufixo -replies) em busca de um registro de resposta. Quando a resposta é recebida, o Uni retornado é concluído com o valor do registro. A operação de envio da requisição gera um ID de correlação e define um cabeçalho (por padrão, REPLY_CORRELATION_ID), que espera que seja enviado de volta no registro de resposta.
O respondendor pode ser implementado usando um processador de Mensageria Reativa (consulte Processando Mensagens).
Para obter mais informações sobre o recurso Kafka Request Reply e as opções avançadas de configuração, consulte a documentação do SmallRye Reactive Messaging .
7. Processando Mensagens
As aplicações que transmitem dados geralmente precisam consumir alguns eventos de um tópico, processá-los e publicar o resultado em um tópico diferente. Um método processador pode ser implementado de forma simples usando as anotações @Incoming e @Outgoing:
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class PriceProcessor {
private static final double CONVERSION_RATE = 0.88;
@Incoming("price-in")
@Outgoing("price-out")
public double process(double price) {
return price * CONVERSION_RATE;
}
}O parâmetro do método process é o conteúdo da mensagem de entrada, enquanto o valor de retorno será usado como conteúdo da mensagem de saída. As assinaturas mencionadas anteriormente para os tipos de parâmetro e retorno também são compatíveis, como Message<T>, Record<K, V>, etc.
É possível aplicar o processamento assíncrono de fluxos consumindo e devolvendo o tipo de fluxo reativo Multi<T>:
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import io.smallrye.mutiny.Multi;
@ApplicationScoped
public class PriceProcessor {
private static final double CONVERSION_RATE = 0.88;
@Incoming("price-in")
@Outgoing("price-out")
public Multi<Double> process(Multi<Integer> prices) {
return prices.filter(p -> p > 100).map(p -> p * CONVERSION_RATE);
}
}7.1. Propagando a Chave de Registro
Ao processar mensagens, é possível propagar a chave do registro de entrada para o registro de saída.
Ativada com a configuração mp.messaging.outgoing.$channel.propagate-record-key=true, a propagação da chave de registro produz o registro de saída com a mesma chave do registro de entrada.
Se o registro de saída já contiver uma chave, ela não será substituída pela chave do registro de entrada. Se o registro de entrada tiver uma chave nula, será usada a propriedade mp.messaging.outgoing.$channel.key.
7.2. Processamento Exactly-Once (Exatamente Único)
O Kafka Transactions permite gerenciar os deslocamentos do consumidor dentro de uma transação, juntamente com as mensagens produzidas. Isso permite acoplar um consumidor a um produtor transacional em um padrão consume-transforma-produz, também conhecido como processamento exatamente único.
O emissor personalizado KafkaTransactions fornece uma forma de aplicar um processamento exatamente único a uma mensagem Kafka de entrada dentro de uma transação.
O exemplo seguinte inclui um lote de registros Kafka dentro de uma transação.
import jakarta.enterprise.context.ApplicationScoped;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Message;
import org.eclipse.microprofile.reactive.messaging.OnOverflow;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.KafkaRecord;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@ApplicationScoped
public class KafkaExactlyOnceProcessor {
@Channel("prices-out")
@OnOverflow(value = OnOverflow.Strategy.BUFFER, bufferSize = 500) (3)
KafkaTransactions<Integer> txProducer;
@Incoming("prices-in")
public Uni<Void> emitInTransaction(Message<ConsumerRecords<String, Integer>> batch) { (1)
return txProducer.withTransactionAndAck(batch, emitter -> { (2)
for (ConsumerRecord<String, Integer> record : batch.getPayload()) {
emitter.send(KafkaRecord.of(record.key(), record.value() + 1)); (3)
}
return Uni.createFrom().voidItem();
});
}
}| 1 | Recomenda-se usar o processamento exatamente único junto com o modo de consumo em lote. Embora seja possível usá-lo com uma única mensagem do Kafka, isso terá um impacto significativo no desempenho. |
| 2 | A mensagem consumida é passada para o KafkaTransactions#withTransactionAndAck para lidar com os registros de offset e confirmação de mensagem. |
| 3 | O método send grava registros no Kafka dentro da transação, sem aguardar o recebimento do envio pelo broker. As mensagens pendentes de gravação no Kafka serão armazenadas em buffer e liberadas antes de confirmar a transação. Portanto, é recomendável configurar o @OnOverflow bufferSize para que caibam mensagens suficientes, por exemplo, o max.poll.records, quantidade máxima de registros retornados em um lote.
|
Ao usar o processamento exatamente único, as confirmações de deslocamento de mensagens consumidas são tratadas pela transação e, portanto, a aplicação não deve confirmar os deslocamentos por outros meios. O consumidor deve ter enable.auto.commit=false (o padrão) e definir explicitamente commit-strategy=ignore:
mp.messaging.incoming.prices-in.commit-strategy=ignore
mp.messaging.incoming.prices-in.failure-strategy=ignore7.2.1. Tratamento de erros para o processamento exatamente único
O Uni retornado do KafkaTransactions#withTransaction produzirá uma falha se a transação falhar e for abortada. A aplicação pode optar por tratar o caso de erro, mas se um Uni com falha for retornado do método @Incoming, o canal de entrada falhará efetivamente e interromperá o fluxo reativo.
O método KafkaTransactions#withTransactionAndAck reconhece e não reconhece a mensagem, mas não retornará um Uni com falha. As mensagens não reconhecidas serão tratadas pela estratégia de falha do canal de entrada (veja Estratégias de Tratamento de Erros). Configurar failure-strategy=ignore simplesmente redefine o consumidor Kafka para os últimos deslocamentos confirmados e retoma o consumo a partir daí.
8. Acessando clientes Kafka diretamente
Em casos raros, você pode precisar acessar os clientes Kafka subjacentes. KafkaClientService fornece acesso thread-safe a Producer e Consumer.
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.event.Observes;
import jakarta.inject.Inject;
import org.apache.kafka.clients.producer.ProducerRecord;
import io.quarkus.runtime.StartupEvent;
import io.smallrye.reactive.messaging.kafka.KafkaClientService;
import io.smallrye.reactive.messaging.kafka.KafkaConsumer;
import io.smallrye.reactive.messaging.kafka.KafkaProducer;
@ApplicationScoped
public class PriceSender {
@Inject
KafkaClientService clientService;
void onStartup(@Observes StartupEvent startupEvent) {
KafkaProducer<String, Double> producer = clientService.getProducer("generated-price");
producer.runOnSendingThread(client -> client.send(new ProducerRecord<>("prices", 2.4)))
.await().indefinitely();
}
}|
A |
Você também pode obter a configuração do Kafka injetada na sua aplicação e criar diretamente clientes produtores, consumidores e administradores do Kafka:
import io.smallrye.common.annotation.Identifier;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.KafkaAdminClient;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.inject.Produces;
import jakarta.inject.Inject;
import java.util.HashMap;
import java.util.Map;
@ApplicationScoped
public class KafkaClients {
@Inject
@Identifier("default-kafka-broker")
Map<String, Object> config;
@Produces
AdminClient getAdmin() {
Map<String, Object> copy = new HashMap<>();
for (Map.Entry<String, Object> entry : config.entrySet()) {
if (AdminClientConfig.configNames().contains(entry.getKey())) {
copy.put(entry.getKey(), entry.getValue());
}
}
return KafkaAdminClient.create(copy);
}
}O mapa de configuração default-kafka-broker contém todas as propriedades da aplicação prefixadas com kafka. ou KAFKA_. Para mais opções de configuração, consulte Resolução de Configuração do Kafka.
9. Serialização JSON
O Quarkus tem capacidades incorporadas para lidar com mensagens JSON Kafka.
Imagine que temos uma classe de dados Fruit da seguinte forma:
public class Fruit {
public String name;
public int price;
public Fruit() {
}
public Fruit(String name, int price) {
this.name = name;
this.price = price;
}
}E queremos utilizá-la para receber mensagens do Kafka, fazer alguma transformação de preços e enviar mensagens de volta para o Kafka.
import io.smallrye.reactive.messaging.annotations.Broadcast;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import jakarta.enterprise.context.ApplicationScoped;
/**
* A bean consuming data from the "fruit-in" channel and applying some price conversion.
* The result is pushed to the "fruit-out" channel.
*/
@ApplicationScoped
public class FruitProcessor {
private static final double CONVERSION_RATE = 0.88;
@Incoming("fruit-in")
@Outgoing("fruit-out")
@Broadcast
public Fruit process(Fruit fruit) {
fruit.price = fruit.price * CONVERSION_RATE;
return fruit;
}
}Para isso, precisamos configurar a serialização JSON com Jackson ou JSON-B.
Com a serialização JSON corretamente configurada, também é possível utilizar Publisher<Fruit> e Emitter<Fruit>.
|
9.1. Serialização via Jackson
O Quarkus possui suporte embutido para serialização e desserialização JSON baseado no Jackson. Ele também irá gerar o serializador e desserializador para você, então você não precisa configurar nada. Quando a geração está desativada, você pode usar os ObjectMapperSerializer e ObjectMapperDeserializer fornecidos, como explicado abaixo.
Existe um ObjectMapperSerializer que pode ser usado para serializar todos os objetos de dados via Jackson. Você pode criar uma subclasse vazia se quiser usar Detecção automática de serializador/desserializador.
Por padrão, o ObjectMapperSerializer serializa null como a String "null". Isso pode ser personalizado com a definição da propriedade de configuração do Kafka json.serialize.null-as-null=true, que serializará null como null. Isso é útil quando se usa um tópico compactado, pois null é usado como uma tombstone para saber quais mensagens são excluídas durante a fase de compactação.
|
A classe correspondente do desserializador precisa ser uma subclasse. Portanto, vamos criar um FruitDeserializer que estende o ObjectMapperDeserializer.
package com.acme.fruit.jackson;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class FruitDeserializer extends ObjectMapperDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}Por fim, configure os seus canais para utilizarem o serializador e desserializador Jackson.
# Configure the Kafka source (we read from it)
mp.messaging.incoming.fruit-in.topic=fruit-in
mp.messaging.incoming.fruit-in.value.deserializer=com.acme.fruit.jackson.FruitDeserializer
# Configure the Kafka sink (we write to it)
mp.messaging.outgoing.fruit-out.topic=fruit-out
mp.messaging.outgoing.fruit-out.value.serializer=io.quarkus.kafka.client.serialization.ObjectMapperSerializerAgora, suas mensagens Kafka conterão uma representação serializada pelo Jackson do seu objeto de dados Fruit. Nesse caso, a configuração do deserializer não é necessária, pois a Detecção automática de serializador/desserializador está habilitada por padrão.
Se você pretende desserializar uma lista de fruits, tem de criar um desserializador com um Jackson TypeReference denotando a coleção genérica utilizada.
package com.acme.fruit.jackson;
import java.util.List;
import com.fasterxml.jackson.core.type.TypeReference;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class ListOfFruitDeserializer extends ObjectMapperDeserializer<List<Fruit>> {
public ListOfFruitDeserializer() {
super(new TypeReference<List<Fruit>>() {});
}
}9.2. Serialização via JSON-B
Em primeiro lugar, é necessário incluir a extensão quarkus-jsonb.
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-jsonb</artifactId>
</dependency>implementation("io.quarkus:quarkus-jsonb")Existe um JsonbSerializer que pode ser usado para serializar todos os objetos de dados via JSON-B. Você pode criar uma subclasse vazia se quiser usar Detecção automática de serializador/desserializador.
Por padrão, o JsonbSerializer serializa null como a String "null". Isso pode ser personalizado com a definição da propriedade de configuração do Kafka json.serialize.null-as-null=true, que serializará null como null. Isso é útil quando se usa um tópico compactado, pois null é usado como uma tombstone para saber quais mensagens são excluídas durante a fase de compactação.
|
A classe correspondente do desserializador precisa ser uma subclasse. Portanto, vamos criar um FruitDeserializer que estende o genérico JsonbDeserializer.
package com.acme.fruit.jsonb;
import io.quarkus.kafka.client.serialization.JsonbDeserializer;
public class FruitDeserializer extends JsonbDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}Por fim, configure os seus canais para utilizarem o serializador e desserializador JSON-B.
# Configure the Kafka source (we read from it)
mp.messaging.incoming.fruit-in.connector=smallrye-kafka
mp.messaging.incoming.fruit-in.topic=fruit-in
mp.messaging.incoming.fruit-in.value.deserializer=com.acme.fruit.jsonb.FruitDeserializer
# Configure the Kafka sink (we write to it)
mp.messaging.outgoing.fruit-out.connector=smallrye-kafka
mp.messaging.outgoing.fruit-out.topic=fruit-out
mp.messaging.outgoing.fruit-out.value.serializer=io.quarkus.kafka.client.serialization.JsonbSerializerAgora, as suas mensagens Kafka conterão uma representação serializada JSON-B do seu objeto de dados Fruit.
Para desserializar uma lista de fruits, é necessário criar um desserializador com um Tipo denotando a coleção genérica utilizada.
package com.acme.fruit.jsonb;
import java.lang.reflect.Type;
import java.util.ArrayList;
import java.util.List;
import io.quarkus.kafka.client.serialization.JsonbDeserializer;
public class ListOfFruitDeserializer extends JsonbDeserializer<List<Fruit>> {
public ListOfFruitDeserializer() {
super(new ArrayList<MyEntity>() {}.getClass().getGenericSuperclass());
}
}
Se não quiser criar um desserializador para cada objeto de dados, você pode usar o genérico io.vertx.kafka.client.serialization.JsonObjectDeserializer que desserializará para um io.vertx.core.json.JsonObject. O serializador correspondente também pode ser usado: io.vertx.kafka.client.serialization.JsonObjectSerializer.
|
10. Serialização Avro
Isso é descrito em um guia dedicado: Usando Apache Kafka com Registro de Esquema e o Avro.
11. Serialização do Esquema JSON
Isso é descrito em um guia dedicado: Usando Apache Kafka com Registro de Esquema e Esquema JSON.
12. Detecção automática de serializador/desserializador
Ao usar a Mensageria Quarkus com Kafka (io.quarkus:quarkus-messaging-kafka), o Quarkus pode frequentemente detectar automaticamente a classe correta de serializador e desserializador. Essa detecção automática é baseada nas declarações dos métodos @Incoming e @Outgoing, assim como nos @Channels injetados.
Por exemplo, se você declarar
@Outgoing("generated-price")
public Multi<Integer> generate() {
...
}e a sua configuração indicar que o canal generated-price utiliza o conector smallrye-kafka, o Quarkus definirá automaticamente o value.serializer para o IntegerSerializer incorporado no Kafka.
Da mesma forma, se você declarar
@Incoming("my-kafka-records")
public void consume(Record<Long, byte[]> record) {
...
}e a sua configuração indicar que o canal my-kafka-records utiliza o conector smallrye-kafka, então o Quarkus definirá automaticamente o key.deserializer para o LongDeserializer incorporado no Kafka, bem como o value.deserializer para ByteArrayDeserializer.
Finalmente, se você declarar
@Inject
@Channel("price-create")
Emitter<Double> priceEmitter;e a sua configuração indicar que o canal price-create utiliza o conector smallrye-kafka, o Quarkus definirá automaticamente o value.serializer para o DoubleSerializer incorporado no Kafka.
O conjunto completo de tipos suportados pela autodetecção do serializador/desserializador é:
-
shortejava.lang.Short -
intejava.lang.Integer -
longejava.lang.Long -
floatejava.lang.Float -
doubleejava.lang.Double -
byte[] -
java.lang.String -
java.util.UUID -
java.nio.ByteBuffer -
org.apache.kafka.common.utils.Bytes -
io.vertx.core.buffer.Buffer -
io.vertx.core.json.JsonObject -
io.vertx.core.json.JsonArray -
classes para as quais existe uma implementação direta de
org.apache.kafka.common.serialization.Serializer<T>/org.apache.kafka.common.serialization.Deserializer<T>.-
a implementação tem de especificar o argumento do tipo
Tcomo o tipo (des)serializado.
-
-
classes geradas a partir de esquemas Avro, bem como Avro
GenericRecord, se o Confluent ou o Apicurio Registry serde estiver presente-
no caso de existirem vários serdes Avro, o serializador/desserializador deve ser configurado manualmente para as classes geradas pelo Avro, uma vez que a detecção automática é impossível
-
consulte Usando Apache Kafka com Registro de Esquema e Avro para obter mais informações sobre a utilização das bibliotecas Confluent ou Apicurio Registry
-
-
classes para as quais uma subclasse de
ObjectMapperSerializer/ObjectMapperDeserializerestá presente, conforme descrito em Serialização via Jackson-
tecnicamente não é necessário criar subclasse de
ObjectMapperSerializer, mas, nesse caso, a detecção automática não é possível
-
-
classes para as quais uma subclasse de
JsonbSerializer/JsonbDeserializerestá presente, conforme descrito em Serialização via JSON-B-
tecnicamente não é necessário criar subclasse de
JsonbSerializer, mas, nesse caso, a detecção automática não é possível
-
Se um serializador/desserializador for definido pela configuração, não será substituído pela detecção automática.
Se você tiver algum problema com a detecção automática de serializadores, pode desativá-la completamente definindo quarkus.messaging.kafka.serializer-autodetection.enabled=false. Se achar que precisa fazer isso, por favor, registre um bug no Quarkus issue tracker para que possamos corrigir o problema.
13. Geração de serializador/desserializador JSON
O Quarkus gera automaticamente serializadores e desserializadores para canais onde:
-
o serializador/desserializador não está configurado
-
a detecção automática não encontrou um serializador/desserializador correspondente
Utiliza Jackson por baixo.
Esta geração pode ser desativada utilizando:
quarkus.messaging.kafka.serializer-generation.enabled=false
A geração não suporta coleções como List<Fruit>. Consulte Serialização via Jackson para escrever seu próprio serializador/desserializador para este caso.
|
14. Usando Registro de Esquemas
Isso é descrito em um guia dedicado para Avro: Usando Apache Kafka com Registro de Esquema e Avro. E um outro para Esquema JSON: Usando Apache Kafka com Registro de Esquema e Esquema JSON.
15. Verificações de Integridade
O Quarkus fornece várias verificações de integridade para o Kafka. Essas verificações são usadas em conjunto com a extensão quarkus-smallrye-health.
15.1. Verificação de Prontidão do Broker Kafka
Ao usar a extensão quarkus-kafka-client, você pode ativar a verificação de integridade da prontidão definindo a propriedade quarkus.kafka.health.enabled como true no seu application.properties. Essa verificação informa o status da interação com um broker Kafka padrão (configurado usando kafka.bootstrap.servers). Ela requer uma conexão de administrador com o broker Kafka e está desativada por padrão. Se estiver ativada, quando o usuário acessar o endpoint /q/health/ready da sua aplicação, terá informações sobre o status de validação da conexão.
15.2. Verificações de Integridade da Mensageria Reativa do Kafka
Quando usar Mensageria Reativa e o conector Kafka, cada canal configurado (de entrada ou de saída) fornece verificações de inicialização, vivacidade e prontidão.
-
A verificação de inicialização verifica se a comunicação com o cluster Kafka está estabelecida.
-
A verificação de vivacidade capta qualquer falha irrecuperável que ocorra durante a comunicação com o Kafka.
-
A verificação de prontidão verifica se o conector Kafka está pronto para consumir/produzir mensagens para os tópicos Kafka configurados.
Para cada canal, é possível desativar as verificações utilizando:
# Disable both liveness and readiness checks with `health-enabled=false`:
# Incoming channel (receiving records form Kafka)
mp.messaging.incoming.your-channel.health-enabled=false
# Outgoing channel (writing records to Kafka)
mp.messaging.outgoing.your-channel.health-enabled=false
# Disable only the readiness check with `health-readiness-enabled=false`:
mp.messaging.incoming.your-channel.health-readiness-enabled=false
mp.messaging.outgoing.your-channel.health-readiness-enabled=false
Você pode configurar o bootstrap.servers para cada canal usando a propriedade mp.messaging.incoming|outgoing.$channel.bootstrap.servers. O padrão é kafka.bootstrap.servers.
|
As verificações de inicialização e prontidão da Mensageria Reativa oferecem duas estratégias. A estratégia padrão verifica se uma conexão ativa foi estabelecida com o broker. Essa abordagem não é intrusiva, pois se baseia em métricas incorporadas do cliente Kafka.
Usando o atributo health-topic-verification-enabled=true, a sonda de inicialização usa um cliente administrador para verificar a lista de tópicos. Já a sonda de prontidão para um canal de entrada verifica se pelo menos uma partição está atribuída para consumo e, para um canal de saída, verifica se o tópico usado pelo produtor existe no broker.
Observe que, para isso, é necessária uma conexão de administrador. Você pode ajustar o tempo limite das chamadas de verificação de tópico para o broker usando a configuração health-topic-verification-timeout.
16. Observabilidade
Se a extensão OpenTelemetry estiver presente, os canais do conector Kafka funcionam sem problemas com o OpenTelemetry Tracing. As mensagens escritas nos tópicos Kafka propagam o span de rastreamento atual. Nos canais de entrada, se um registro Kafka consumido contiver informações de rastreamento, o processamento da mensagem herda o span da mensagem como pai.
O rastreamento pode ser desativado explicitamente por canal:
mp.messaging.incoming.data.tracing-enabled=falseSe a extensão Micrometer está presente, então as métricas dos clientes produtor e consumidor do Kafka são expostas como medidores do Micrometer.
16.1. Métricas do canal
Métricas específicas por canal também podem ser coletadas e expostas como medidores do Micrometer. As seguintes métricas podem ser coletadas por canal, identificadas com a tag channel:
-
quarkus.messaging.message.count: O número de mensagens produzidas ou recebidas -
quarkus.messaging.message.acks: Número de mensagens processadas com êxito -
quarkus.messaging.message.failures: Número de mensagens processadas com falhas -
quarkus.messaging.message.duration: A duração do processamento da mensagem.
Por motivos de compatibilidade com versões anteriores, as métricas de canal não são ativadas por padrão e podem ser ativadas com:
|
A observação de mensagens depende da interceptação de mensagens e, portanto, não suporta canais que consomem mensagens com um tipo de mensagem personalizado, como A interceptação e observação de mensagens ainda funcionam com canais que consomem o tipo genérico |
smallrye.messaging.observation.enabled=true17. Fluxos Kafka
Isso é descrito em um guia dedicado: Usando Fluxos do Apache Kafka.
18. Usando Snappy para compressão de mensagens
Nos canais de saída, você pode ativar a compressão Snappy definindo o atributo compression.type para snappy:
mp.messaging.outgoing.fruit-out.compression.type=snappyNo modo JVM, ele funcionará imediatamente. No entanto, para compilar sua aplicação em um executável nativo, você precisa adicionar quarkus.kafka.snappy.enabled=true ao seu application.properties.
No modo nativo, o Snappy está desativado por padrão, uma vez que a utilização do Snappy requer a incorporação de uma biblioteca nativa e a sua descompactação quando a aplicação é iniciada.
19. Disabling JMX MBean registration
To disable JMX MBean registration, set the following property in your application.properties:
quarkus.kafka.jmx.enabled=falseWhen disabled, the AppInfoParser skipş the JMX MBean registration and the default value for kafka.metric.reporters is set to empty, preventing the JmxReporter from being loaded.
Kafka client metrics are available through Micrometer when the Micrometer extension is present.
20. Autenticação com OAuth
Se o seu broker Kafka usar o OAuth como mecanismo de autenticação, você precisará configurar o consumidor Kafka para habilitar esse processo de autenticação. Primeiro, adicione a seguinte dependência à sua aplicação:
<dependency>
<groupId>io.strimzi</groupId>
<artifactId>kafka-oauth-client</artifactId>
</dependency>
<!-- if compiling to native you'd need also the following dependency -->
<dependency>
<groupId>io.strimzi</groupId>
<artifactId>kafka-oauth-common</artifactId>
</dependency>implementation("io.strimzi:kafka-oauth-client")
// if compiling to native you'd need also the following dependency
implementation("io.strimzi:kafka-oauth-common")Essa dependência fornece o manipulador de retorno de chamada necessário para lidar com o fluxo de trabalho do OAuth. Em seguida, em application.properties, adicione:
mp.messaging.connector.smallrye-kafka.security.protocol=SASL_PLAINTEXT
mp.messaging.connector.smallrye-kafka.sasl.mechanism=OAUTHBEARER
mp.messaging.connector.smallrye-kafka.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \
oauth.client.id="team-a-client" \
oauth.client.secret="team-a-client-secret" \
oauth.token.endpoint.uri="http://keycloak:8080/auth/realms/kafka-authz/protocol/openid-connect/token" ;
mp.messaging.connector.smallrye-kafka.sasl.login.callback.handler.class=io.strimzi.kafka.oauth.client.JaasClientOauthLoginCallbackHandler
quarkus.ssl.native=trueAtualize os valores oauth.client.id, oauth.client.secret e oauth.token.endpoint.uri.
A autenticação OAuth funciona nos modos JVM e nativo. Como o SSL não é habilitado por padrão no modo nativo, quarkus.ssl.native=true deve ser adicionado para dar suporte ao JaasClientOauthLoginCallbackHandler, que usa SSL. (Consulte o guia Usando SSL com Executáveis Nativos para obter mais detalhes.)
21. Configuração de TLS
A extensão do cliente Kafka integra-se ao registro TLS do Quarkus para configurar clientes.
Para configurar o TLS para a configuração padrão do Kafka, você precisa fornecer uma configuração TLS nomeada no site application.properties :
quarkus.tls.your-tls-config.trust-store.pem.certs=target/certs/kafka.crt,target/certs/kafka-ca.crt
# ...
kafka.tls-configuration-name=your-tls-config
# enable ssl security protocol
kafka.security.protocol=sslIsso, por sua vez, fornecerá ao cliente Kafka uma implementação do ssl.engine.factory.class .
|
Certifique-se também de ativar o protocolo de segurança do canal SSL usando a propriedade |
Os canais do Quarkus Messaging podem ser configurados individualmente para usar uma configuração TLS específica:
mp.messaging.incoming.your-channel.tls-configuration-name=your-tls-config
mp.messaging.incoming.your-channel.security.protocol=ssl22. Testando uma aplicação Kafka
22.1. Testando sem um broker
Pode ser útil testar a aplicação sem ter que iniciar um broker Kafka. Para isso, você pode trocar os canais gerenciados pelo conector Kafka para a em memória.
| Esta abordagem só funciona para testes JVM. Não pode ser utilizada para testes nativos (porque estes não suportam a injeção). |
Digamos que queremos testar a seguinte aplicação de processador:
@ApplicationScoped
public class BeverageProcessor {
@Incoming("orders")
@Outgoing("beverages")
Beverage process(Order order) {
System.out.println("Order received " + order.getProduct());
Beverage beverage = new Beverage();
beverage.setBeverage(order.getProduct());
beverage.setCustomer(order.getCustomer());
beverage.setOrderId(order.getOrderId());
beverage.setPreparationState("RECEIVED");
return beverage;
}
}Em primeiro lugar, adicione a seguinte dependência de teste à sua aplicação:
<dependency>
<groupId>io.smallrye.reactive</groupId>
<artifactId>smallrye-reactive-messaging-in-memory</artifactId>
<scope>test</scope>
</dependency>testImplementation("io.smallrye.reactive:smallrye-reactive-messaging-in-memory")Em seguida, crie um recurso de teste Quarkus da seguinte forma:
public class KafkaTestResourceLifecycleManager implements QuarkusTestResourceLifecycleManager {
@Override
public Map<String, String> start() {
Map<String, String> env = new HashMap<>();
Map<String, String> props1 = InMemoryConnector.switchIncomingChannelsToInMemory("orders"); (1)
Map<String, String> props2 = InMemoryConnector.switchOutgoingChannelsToInMemory("beverages"); (2)
env.putAll(props1);
env.putAll(props2);
return env; (3)
}
@Override
public void stop() {
InMemoryConnector.clear(); (4)
}
}| 1 | Mude o canal de entrada orders (esperando mensagens do Kafka) para em memória. |
| 2 | Mude o canal de saída beverages (escrever mensagens para o Kafka) para em memória. |
| 3 | Constrói e devolve um Map que contém todas as propriedades necessárias para configurar a aplicação para utilizar canais em memória. |
| 4 | Quando o teste parar, limpe o InMemoryConnector (elimine todas as mensagens recebidas e enviadas) |
Crie um teste Quarkus utilizando o recurso de teste criado acima:
import static org.awaitility.Awaitility.await;
@QuarkusTest
@QuarkusTestResource(KafkaTestResourceLifecycleManager.class)
class BaristaTest {
@Inject
@Connector("smallrye-in-memory")
InMemoryConnector connector; (1)
@Test
void testProcessOrder() {
InMemorySource<Order> ordersIn = connector.source("orders"); (2)
InMemorySink<Beverage> beveragesOut = connector.sink("beverages"); (3)
Order order = new Order();
order.setProduct("coffee");
order.setName("Coffee lover");
order.setOrderId("1234");
ordersIn.send(order); (4)
await().<List<? extends Message<Beverage>>>until(beveragesOut::received, t -> t.size() == 1); (5)
Beverage queuedBeverage = beveragesOut.received().get(0).getPayload();
Assertions.assertEquals(Beverage.State.READY, queuedBeverage.getPreparationState());
Assertions.assertEquals("coffee", queuedBeverage.getBeverage());
Assertions.assertEquals("Coffee lover", queuedBeverage.getCustomer());
Assertions.assertEquals("1234", queuedBeverage.getOrderId());
}
}| 1 | Injete o conector em memória na sua classe de teste. |
| 2 | Recupere o canal de entrada (orders) - o canal deve ter sido trocado para em memória no recurso de teste. |
| 3 | Recuperar o canal de saída (beverages) - o canal deve ter sido trocado para em memória no recurso de teste. |
| 4 | Use o método send para enviar uma mensagem ao canal orders. A aplicação processará essa mensagem e enviará uma mensagem ao canal beverages. |
| 5 | Utilize o método received no canal beverages para verificar as mensagens produzidas pela aplicação. |
Se o seu consumidor Kafka for baseado em lotes, você precisará enviar um lote de mensagens para o canal, criando-as manualmente.
Por exemplo:
@ApplicationScoped
public class BeverageProcessor {
@Incoming("orders")
CompletionStage<Void> process(KafkaRecordBatch<String, Order> orders) {
System.out.println("Order received " + orders.getPayload().size());
return orders.ack();
}
}import static org.awaitility.Awaitility.await;
@QuarkusTest
@QuarkusTestResource(KafkaTestResourceLifecycleManager.class)
class BaristaTest {
@Inject
@Connector("smallrye-in-memory")
InMemoryConnector connector;
@Test
void testProcessOrder() {
InMemorySource<IncomingKafkaRecordBatch<String, Order>> ordersIn = connector.source("orders");
var committed = new AtomicBoolean(false); (1)
var commitHandler = new KafkaCommitHandler() {
@Override
public <K, V> Uni<Void> handle(IncomingKafkaRecord<K, V> record) {
committed.set(true); (2)
return null;
}
};
var failureHandler = new KafkaFailureHandler() {
@Override
public <K, V> Uni<Void> handle(IncomingKafkaRecord<K, V> record, Throwable reason, Metadata metadata) {
return null;
}
};
Order order = new Order();
order.setProduct("coffee");
order.setName("Coffee lover");
order.setOrderId("1234");
var record = new ConsumerRecord<>("topic", 0, 0, "key", order);
var records = new ConsumerRecords<>(Map.of(new TopicPartition("topic", 1), List.of(record)));
var batch = new IncomingKafkaRecordBatch<>(
records, "kafka", 0, commitHandler, failureHandler, false, false); (3)
ordersIn.send(batch);
await().until(committed::get); (4)
}
}| 1 | Crie um AtomicBoolean para rastrear se o lote foi confirmado. |
| 2 | Atualize committed quando o lote for confirmado. |
| 3 | Crie um IncomingKafkaRecordBatch com um único registro. |
| 4 | Aguarde até que o lote seja confirmado. |
|
Com os canais em memória, pudemos testar o código da aplicação processando mensagens sem iniciar um broker Kafka. Note que os diferentes canais em memória são independentes, e a troca do conector do canal para em memória não simula a entrega de mensagens entre canais configurados para o mesmo tópico do Kafka. |
22.1.1. Propagação de contexto com InMemoryConnector
Por padrão, canais em memória enviam mensagens na thread do chamador, que seria a thread principal em testes de unidade.
A dependência quarkus-test-vertx provê a anotação @io.quarkus.test.vertx.RunOnVertxContext, que quando usada em um método de teste, executa o teste em um contexto do Vert.x.
No entando, a maioria dos outros conectores lidam com a propagação de contexto enviando mensagens em contextos Vert.x duplicados separados.
Se os seus testes são dependentes da propagação de contexto, você pode configurar os canais de conector em memória com o atributo run-on-vertx-context para enviar eventos, incluindo mensagens e reconhecimentos, em um contexto Vert.x. Alternativamente você pode trocar esse comportamento usando o método InMemorySource#runOnVertxContext.
22.2. Testando usando um broker Kafka
Se você estiver usando Dev Services para o Kafka, um broker Kafka será iniciado e estará disponível durante os testes, a menos que seja desativado no perfil %test. Embora seja possível conectar-se a este broker usando a API do Kafka Clients, A Biblioteca Companheira do Kafka propõe uma forma mais fácil de interagir com um broker Kafka e criar ações de consumidor, produtor e administrador dentro dos testes.
Para utilizar a API KafkaCompanion nos testes, comece adicionando a seguinte dependência:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-test-kafka-companion</artifactId>
<scope>test</scope>
</dependency>que fornece io.quarkus.test.kafka.KafkaCompanionResource - uma implementação de io.quarkus.test.common.QuarkusTestResourceLifecycleManager.
Em seguida, utilize @QuarkusTestResource para configurar o Kafka Companion em testes, por exemplo:
import static org.junit.jupiter.api.Assertions.assertEquals;
import java.util.UUID;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.junit.jupiter.api.Test;
import io.quarkus.test.common.QuarkusTestResource;
import io.quarkus.test.junit.QuarkusTest;
import io.quarkus.test.kafka.InjectKafkaCompanion;
import io.quarkus.test.kafka.KafkaCompanionResource;
import io.smallrye.reactive.messaging.kafka.companion.ConsumerTask;
import io.smallrye.reactive.messaging.kafka.companion.KafkaCompanion;
@QuarkusTest
@QuarkusTestResource(KafkaCompanionResource.class)
public class OrderProcessorTest {
@InjectKafkaCompanion (1)
KafkaCompanion companion;
@Test
void testProcessor() {
companion.produceStrings().usingGenerator(i -> new ProducerRecord<>("orders", UUID.randomUUID().toString())); (2)
// Expect that the tested application processes orders from 'orders' topic and write to 'orders-processed' topic
ConsumerTask<String, String> orders = companion.consumeStrings().fromTopics("orders-processed", 10); (3)
orders.awaitCompletion(); (4)
assertEquals(10, orders.count());
}
}| 1 | @InjectKafkaCompanion injeta a instância KafkaCompanion, configurada para acessar o broker Kafka criado para os testes. |
| 2 | Utilize KafkaCompanion para criar uma tarefa de produção que escreva 10 registros no tópico 'orders'. |
| 3 | Crie uma tarefa de consumidor que subscreva o tópico 'orders-processed' e consuma 10 registros. |
| 4 | Aguarde a conclusão da tarefa do consumidor. |
|
Você precisa configurar Caso contrário, você receberá um |
|
Se o Dev Service Kafka estiver disponível durante os testes, A configuração do broker Kafka criado pode ser personalizada usando |
22.2.1. Recurso de teste personalizado
Como alternativa, você pode iniciar um broker Kafka em um recurso de teste. O trecho a seguir mostra um recurso de teste iniciando um broker do Kafka usando Testcontainers :
public class KafkaResource implements QuarkusTestResourceLifecycleManager {
private final KafkaContainer kafka = new KafkaContainer();
@Override
public Map<String, String> start() {
kafka.start();
return Collections.singletonMap("kafka.bootstrap.servers", kafka.getBootstrapServers()); (1)
}
@Override
public void stop() {
kafka.close();
}
}| 1 | Configure a localização do bootstrap do Kafka, para que a aplicação se ligue a este broker. |
23. Dev Services para o Kafka
If any Kafka-related extension is present (e.g. quarkus-messaging-kafka), Dev Services for Kafka automatically starts a Kafka broker in dev mode and when running tests.
So, you don’t have to start a broker manually.
The application is configured automatically.
| By default, Dev Services for Kafka uses the Apache Kafka native image which starts in ~1 second. |
23.1. Ativar/desativar Dev Services para o Kafka
Os Dev Services para o Kafka é ativado automaticamente, a menos que:
-
quarkus.kafka.devservices.enabledesteja definido comofalse -
o
kafka.bootstrap.serversesteja configurado -
todos os canais Kafka de mensagens reativas tenham o atributo
bootstrap.serversdefinido
Dev Services for Kafka relies on Docker to start the broker.
If your environment does not support Docker, you will need to start the broker manually, or connect to an already running broker.
You can configure the broker address using kafka.bootstrap.servers.
23.2. broker compartilhado
Most of the time you need to share the broker between applications. Dev Services for Kafka implements a service discovery mechanism for your multiple Quarkus applications running in dev mode to share a single broker.
O Dev Services para o Kafka inicia o broker com a etiqueta quarkus-dev-service-kafka que é utilizada para identificar o container.
|
If you need multiple (shared) brokers, you can configure the quarkus.kafka.devservices.service-name attribute and indicate the broker name.
It looks for a container with the same value, or starts a new one if none can be found.
The default service name is kafka.
Sharing is enabled by default in dev mode, but disabled in test mode.
You can disable the sharing with quarkus.kafka.devservices.shared=false.
23.3. Definindo a porta
By default, Dev Services for Kafka picks a random port and configures the application.
You can set the port by configuring the quarkus.kafka.devservices.port property.
Note que o endereço anunciado do Kafka é automaticamente configurado com a porta escolhida.
23.4. Configurando a imagem
Dev Services for Kafka supports the following container providers:
upstream-kafka-native (default) uses the official Apache Kafka native image, compiled with GraalVM for fast startup.
upstream-kafka uses the official Apache Kafka JVM image.
quarkus.kafka.devservices.provider=upstream-kafkaRedpanda is a Kafka compatible event streaming platform. You can select any version from https://hub.docker.com/r/redpandadata/redpanda.
quarkus.kafka.devservices.provider=redpandaStrimzi provides container images and Operators for running Apache Kafka on Kubernetes. While Strimzi is optimized for Kubernetes, the images work perfectly in classic container environments. Strimzi container images run a Kafka broker on JVM, which is slower to start.
quarkus.kafka.devservices.provider=strimziPara o Strimzi, você pode selecionar qualquer imagem com uma versão Kafka que tenha suporte para o Kraft (2.8.1 e superior) em https://quay.io/repository/strimzi-test-container/test-container?tab=tags
quarkus.kafka.devservices.image-name=quay.io/strimzi-test-container/test-container:0.115.0-kafka-4.2.023.5. Configurando os tópicos no Kafka
You can configure the Dev Services for Kafka to create topics once the broker is started. Topics are created with given number of partitions and 1 replica. The syntax is the following:
quarkus.kafka.devservices.topic-partitions.<topic-name>=<number-of-partitions>The following example creates a topic named test with three partitions, and a second topic named messages with two partitions.
quarkus.kafka.devservices.topic-partitions.test=3
quarkus.kafka.devservices.topic-partitions.messages=2If a topic already exists with the given name, the creation is skipped, without trying to re-partition the existing topic to a different number of partitions.
Você pode configurar o tempo limite para as chamadas do client admin do Kafka utilizadas na criação de tópicos utilizando quarkus.kafka.devservices.topic-partitions-timeout. A predefinição é de 2 segundos.
23.6. Suporte aos producers transacionais e idempotentes
By default, the Redpanda broker is configured to enable transactions and idempotence features. You can disable those using:
quarkus.kafka.devservices.redpanda.transaction-enabled=false| As transações Redpanda não suportam um processamento exatamente único. |
23.7. Compose
The Kafka Dev Services supports Compose Dev Services.
It relies on a compose-devservices.yml, such as:
name: <application name>
services:
kafka:
image: apache/kafka-native:4.2.0
restart: "no"
ports:
- '9092'
labels:
io.quarkus.devservices.compose.exposed_ports: /etc/kafka/docker/ports
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9093
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_NUM_PARTITIONS: 3
command: "/kafka.sh"
volumes:
- './kafka.sh:/kafka.sh'For the broker to advertise its externally accessible address to clients, it requires an additional file kafka.sh as described in Exposing port mappings to running containers.
23.8. Configuration reference
Configuration property fixed at build time - All other configuration properties are overridable at runtime
Configuration property |
Tipo |
Padrão |
|---|---|---|
If Dev Services for Kafka has been explicitly enabled or disabled. Dev Services are generally enabled by default, unless there is an existing configuration present. For Kafka, Dev Services starts a broker unless Environment variable: Show more |
booleano |
|
Optional fixed port the dev service will listen to. If not defined, the port will be chosen randomly. Environment variable: Show more |
int |
|
Kafka dev service container type. Redpanda, Strimzi, kafka-native and upstream kafka container providers are supported. Default is upstream-kafka-native. For Redpanda: See https://docs.redpanda.com/current/get-started/quick-start/ and https://hub.docker.com/r/redpandadata/redpanda For Strimzi: See https://github.com/strimzi/test-container and https://quay.io/repository/strimzi-test-container/test-container For Kafka Native: See https://github.com/ozangunalp/kafka-native and https://quay.io/repository/ogunalp/kafka-native For Upstream Kafka: See https://hub.docker.com/r/apache/kafka and https://hub.docker.com/r/apache/kafka-native Environment variable: Show more |
|
|
The Kafka container image to use. Dependent on the provider. Environment variable: Show more |
string |
|
Indicates if the Kafka broker managed by Quarkus Dev Services is shared. When shared, Quarkus looks for running containers using label-based service discovery. If a matching container is found, it is used, and so a second one is not started. Otherwise, Dev Services for Kafka starts a new container. The discovery uses the Container sharing is only used in dev mode. Environment variable: Show more |
booleano |
|
The value of the This property is used when you need multiple shared Kafka brokers. Environment variable: Show more |
string |
|
The topic-partition pairs to create in the Dev Services Kafka broker. After the broker is started, given topics with partitions are created, skipping already existing topics. For example, The topic creation will not try to re-partition existing topics with different number of partitions. Environment variable: Show more |
Map<String,Integer> |
|
Timeout for admin client calls used in topic creation. Defaults to 2 seconds. Environment variable: Show more |
|
|
Environment variables that are passed to the container. Environment variable: Show more |
Map<String,String> |
|
Enables transaction support. Also enables the producer idempotence. Find more info about Redpanda transaction support on https://vectorized.io/blog/fast-transactions/. Notice that KIP-447 (producer scalability for exactly once semantic) and KIP-360 (Improve reliability of idempotent/transactional producer) are not supported. Environment variable: Show more |
booleano |
|
Port to access the Redpanda HTTP Proxy (pandaproxy). If not defined, the port will be chosen randomly. Environment variable: Show more |
int |
|
Configuration properties that will be added to the server properties file provided to the Kafka broker by the Strimzi provider. Environment variable: Show more |
Map<String,String> |
|
About the Duration format
To write duration values, use the standard Você também pode usar um formato simplificado, começando com um número:
Em outros casos, o formato simplificado é traduzido para o formato 'java.time.Duration' para análise:
|
24. Kafka Dev UI
Se alguma extensão relacionada ao Kafka estiver presente (por exemplo, quarkus-messaging-kafka ),
a interface de usuário do Quarkus Dev será ampliada com uma interface de gerenciamento do corretor Kafka.
Ela é conectada automaticamente ao corretor Kafka configurado para o aplicativo.
Com o Kafka Dev UI, pode gerenciar diretamente o seu cluster Kafka e executar tarefas, tais como:
-
Listar e criar tópicos
-
Visualização de registros
-
Publicação de novos registros
-
Inspeção da lista de grupos de consumidores e do respetivo desfasamento de consumo
| A Kafka Dev UI faz parte da interface de desenvolvimento do Quarkus e só está disponível no modo de desenvolvimento. |
25. Vinculações de Serviços do Kubernetes
| O suporte a vinculações de serviços foi depreciado |
A extensão Quarkus Kafka oferece suporte à Especificação de Vinculação de Serviço para Kubernetes. Você pode ativar isso adicionando a extensão quarkus-kubernetes-service-binding à sua aplicação.
Quando executada em clusters Kubernetes configurados adequadamente, a extensão Kafka extrairá sua configuração de conexão do broker Kafka da associação de serviços disponível dentro do cluster, sem a necessidade de configuração do usuário.
26. Modelo de execução
A Mensageria Reativa invoca os métodos do usuário em uma thread de I/O. Portanto, por padrão, os métodos não devem bloquear. Conforme descrito em Bloqueando o processamento, você precisa adicionar a anotação @Blocking no método se ele bloquear a thread do chamador.
Consulte a documentação da Arquitetura Reativa do Quarkus para obter mais informações sobre este tópico.
27. Decoradores de Canais
A Mensageria Reativa do SmallRye suporta a decoração de canais de entrada e saída para implementar preocupações transversais, como monitoramento, rastreamento ou interceptação de mensagens. Para mais informações sobre a implementação de decoradores e interceptadores de mensagens, veja a documentação da Mensageria Reativa do SmallRye.
28. Referência de Configuração
Mais detalhes sobre a configuração da Mensageria Reativa do SmallRye podem ser encontrados na documentação da Mensageria Reativa do SmallRye - Conector Kafka.
|
Cada canal pode ser desativado através da configuração utilizando: |
Os atributos mais importantes são enumerados nos quadros seguintes:
28.1. Configuração do canal de entrada (sondagem a partir do Kafka)
Os seguintes atributos são configurados utilizando:
mp.messaging.incoming.your-channel-name.attribute=valueAlgumas propriedades têm apelidos que podem ser configurados globalmente:
kafka.bootstrap.servers=...Você também pode passar qualquer propriedade suportada pelo consumidor Kafka subjacente.
Por exemplo, para configurar a propriedade max.poll.records, utilize:
mp.messaging.incoming.[channel].max.poll.records=1000Algumas propriedades do cliente consumidor são configuradas com valores predefinidos sensíveis:
Se não estiver definido, reconnect.backoff.max.ms é definido para 10000 para evitar uma carga elevada ao desconectar.
Se não for definido, key.deserializer é definido como org.apache.kafka.common.serialization.StringDeserializer.
O consumidor client.id é configurado de acordo com o número de clientes a criar utilizando a propriedade mp.messaging.incoming.[channel].partitions.
-
Se for fornecido um
client.id, este é usado como está ou sufixado com o índice do cliente se a propriedadepartitionsestiver definida. -
Se não for fornecido um
client.id, este é gerado como[client-id-prefix][channel-name][-index].
| Atributo (alias) | Descrição | Obrigatório | Padrão |
|---|---|---|---|
bootstrap.servers (kafka.bootstrap.servers) |
Uma lista separada por vírgulas de host:port a ser usada para estabelecer a conexão inicial com o cluster Kafka. Tipo: string |
falso |
|
topic |
O tema Kafka consumido/populado. Se nem essa propriedade nem as propriedades 'topics' estiverem definidas, o nome do canal será usado Tipo: string |
falso |
|
health-enabled |
Se o relatório de integridade está habilitado (padrão) ou desabilitado Tipo: boolean |
falso |
|
health-readiness-enabled |
Se o relatório de integridade de prontidão está habilitado (padrão) ou desabilitado Tipo: boolean |
falso |
|
health-readiness-topic-verification |
deprecated - Se a verificação de prontidão deve verificar se os tópicos existem no broker. O padrão é false. Habilitá-lo requer uma conexão de administrador. Deprecated: use 'health-topic-verification-enabled' em vez disso. Tipo: boolean |
falso |
|
health-readiness-timeout |
deprecated - Durante a verificação de integridade de prontidão, o conector se conecta ao broker e recupera a lista de tópicos. Esse atributo especifica a duração máxima (em ms) para a recuperação. Se excedido, o canal é considerado não pronto. Preterido: use 'health-topic-verification-timeout' em vez disso. Tipo: long |
falso |
|
health-topic-verification-enabled |
Se a verificação de inicialização e prontidão deve verificar se os tópicos existem no broker. O padrão é false. Habilitá-lo requer uma conexão de cliente administrador. Tipo: boolean |
falso |
|
health-topic-verification-readiness-disabled |
Whether the topic verification is disabled for the readiness health check. Type: boolean |
falso |
|
health-topic-verification-startup-disabled |
Whether the topic verification is disabled for the startup health check. Type: boolean |
falso |
|
health-topic-verification-timeout |
Durante a verificação de integridade de inicialização e preparação, o conector se conecta ao agente e recupera a lista de tópicos. Esse atributo especifica a duração máxima (em ms) para a recuperação. Se excedido, o canal é considerado não pronto. Tipo: long |
falso |
|
tracing-enabled |
Se o rastreamento está habilitado (padrão) ou desabilitado Tipo: boolean |
falso |
|
client-id-prefix |
Prefix for Kafka client Type: string |
falso |
|
checkpoint.state-store |
While using the Type: string |
falso |
|
checkpoint.state-type |
While using the Type: string |
falso |
|
checkpoint.unsynced-state-max-age.ms |
While using the Type: int |
falso |
|
cloud-events |
Habilita (padrão) ou desabilita o suporte a Cloud Event. Se habilitado em um canal incoming, o conector analisará os registros de entrada e tentará criar metadados do Cloud Event. Se habilitado em um outgoing, o conector enviará as mensagens de saída como Cloud Event se a mensagem incluir Metadados de Evento de Nuvem. Tipo: boolean |
falso |
|
kafka-configuration |
Identificador de um bean CDI que fornece a configuração padrão do consumidor/produtor Kafka para esse canal. A configuração do canal ainda pode substituir qualquer atributo. O bean deve ter um tipo de Map<String, Object> e deve usar o qualificador @io.smallrye.common.annotation.Identifier para definir o identificador. Tipo: string |
falso |
|
topics |
A comma-separated list of topics to be consumed. Cannot be used with the Type: string |
falso |
|
pattern |
Indicate that the Type: boolean |
falso |
|
assign-seek |
Assign partitions and optionally seek to offsets, instead of subscribing to topics. A comma-separating list of triplets in form of Type: string |
falso |
|
key.deserializer |
The deserializer classname used to deserialize the record’s key Type: string |
falso |
|
lazy-client |
Se o cliente Kafka é criado preguiçosamente ou ansiosamente. Tipo: boolean |
falso |
|
value.deserializer |
The deserializer classname used to deserialize the record’s value Type: string |
verdadeiro |
|
fetch.min.bytes |
The minimum amount of data the server should return for a fetch request. The default setting of 1 byte means that fetch requests are answered as soon as a single byte of data is available or the fetch request times out waiting for data to arrive. Type: int |
falso |
|
group.id |
A unique string that identifies the consumer group the application belongs to. If not set, defaults to the application name as set by the If that is not set either, a unique, generated id is used. It is recommended to always define a Type: string |
falso |
|
enable.auto.commit |
If enabled, consumer’s offset will be periodically committed in the background by the underlying Kafka client, ignoring the actual processing outcome of the records. It is recommended to NOT enable this setting and let Reactive Messaging handles the commit. Type: boolean |
falso |
|
retry |
Whether or not the connection to the broker is re-attempted in case of failure Type: boolean |
falso |
|
retry-attempts |
The maximum number of reconnection before failing. -1 means infinite retry Type: int |
falso |
|
retry-max-wait |
The max delay (in seconds) between 2 reconnects Type: int |
falso |
|
broadcast |
Whether the Kafka records should be dispatched to multiple consumer Type: boolean |
falso |
|
auto.offset.reset |
What to do when there is no initial offset in Kafka.Accepted values are earliest, latest and none Type: string |
falso |
|
failure-strategy |
Specify the failure strategy to apply when a message produced from a record is acknowledged negatively (nack). Values can be Type: string |
falso |
|
commit-strategy |
Specify the commit strategy to apply when a message produced from a record is acknowledged. Values can be Type: string |
falso |
|
ordered |
Configures ordering guarantees for concurrent processing. Possible values: Type: string |
falso |
|
ordered.max-concurrency |
Maximum number of groups (keys or partitions) that can be processed concurrently. Defaults to Type: int |
falso |
|
throttled.unprocessed-record-max-age.ms |
While using the Type: int |
falso |
|
dead-letter-queue.topic |
When the Type: string |
falso |
|
dead-letter-queue.producer-client-id |
When the Type: string |
falso |
|
dead-letter-queue.key.serializer |
When the Type: string |
falso |
|
dead-letter-queue.value.serializer |
When the Type: string |
falso |
|
delayed-retry-topic.topics |
When the Type: string |
falso |
|
delayed-retry-topic.max-retries |
When the Type: int |
falso |
|
delayed-retry-topic.timeout |
When the Type: int |
falso |
|
partitions |
deprecated - The number of partitions to be consumed concurrently. The connector creates the specified amount of Kafka consumers. It should match the number of partition of the targeted topic. Deprecated: Use Type: int |
falso |
|
requests |
deprecated - When Type: int |
falso |
|
consumer-rebalance-listener.name |
The name set in Type: string |
falso |
|
key-deserialization-failure-handler |
The name set in Type: string |
falso |
|
value-deserialization-failure-handler |
The name set in Type: string |
falso |
|
fail-on-deserialization-failure |
When no deserialization failure handler is set and a deserialization failure happens, report the failure and mark the application as unhealthy. If set to Type: boolean |
falso |
|
graceful-shutdown |
Whether or not a graceful shutdown should be attempted when the application terminates. Type: boolean |
falso |
|
poll-timeout |
The polling timeout in milliseconds. When polling records, the poll will wait at most that duration before returning records. Default is 1000ms Type: int |
falso |
|
pause-if-no-requests |
Whether the polling must be paused when the application does not request items and resume when it does. This allows implementing back-pressure based on the application capacity. Note that polling is not stopped, but will not retrieve any records when paused. Type: boolean |
falso |
|
batch |
Whether the Kafka records are consumed in batch. The channel injection point must consume a compatible type, such as Type: boolean |
falso |
|
max-queue-size-factor |
Multiplier factor to determine maximum number of records queued for processing, using Type: int |
falso |
|
share-group |
Whether to use Kafka Share Groups for consumption. When enabled, the consumer will use a ShareConsumer which provides cooperative record processing across multiple consumers without explicit partition assignment. Type: boolean |
falso |
|
share-group.failure-acknowledgement-type |
Default acknowledgement type to apply to the record, when the message is nacked. Type: string |
falso |
|
share-group.failure-deserialization-acknowledgement-type |
Default acknowledgement type to apply to the record, when the message is nacked because of failure on deserialization. Type: string |
falso |
|
share-group.unprocessed-record-max-age.ms |
While using share groups, specify the max age in milliseconds that an unprocessed record can be before the connector reports a failure. Setting this attribute to 0 disables this monitoring. Type: int |
falso |
|
28.2. Configuração do canal de saída (escrevendo no Kafka)
Os seguintes atributos são configurados utilizando:
mp.messaging.outgoing.your-channel-name.attribute=valueAlgumas propriedades têm apelidos que podem ser configurados globalmente:
kafka.bootstrap.servers=...Você também pode passar qualquer propriedade suportada pelo produtor Kafka subjacente.
Por exemplo, para configurar a propriedade max.block.ms, utilize:
mp.messaging.outgoing.[channel].max.block.ms=10000Algumas propriedades do cliente produtor são configuradas para valores predefinidos sensíveis:
Se não estiver definido, reconnect.backoff.max.ms é definido para 10000 para evitar uma carga elevada ao desconectar.
Se não for definido, key.serializer é definido como org.apache.kafka.common.serialization.StringSerializer.
Se não for definido, o produtor client.id é gerado como [client-id-prefix][channel-name].
| Atributo (alias) | Descrição | Obrigatório | Padrão |
|---|---|---|---|
acks |
O número de reconhecimentos que o produtor exige que o líder tenha recebido antes de considerar um pedido completo. Isso controla a durabilidade dos registros que são enviados. Os valores aceitos são: 0, 1, todos Tipo: string |
falso |
|
bootstrap.servers (kafka.bootstrap.servers) |
Uma lista separada por vírgulas de host:port a ser usada para estabelecer a conexão inicial com o cluster Kafka. Tipo: string |
falso |
|
buffer.memory |
O total de bytes de memória que o produtor pode usar para armazenar em buffer registros aguardando para serem enviados ao servidor. Tipo: long |
falso |
|
client-id-prefix |
Prefix for Kafka client Type: string |
falso |
|
close-timeout |
A quantidade de milissegundos à espera de um desligamento gracioso do produtor de Kafka Tipo: int |
falso |
|
cloud-events |
Habilita (padrão) ou desabilita o suporte a Cloud Event. Se habilitado em um canal incoming, o conector analisará os registros de entrada e tentará criar metadados do Cloud Event. Se habilitado em um outgoing, o conector enviará as mensagens de saída como Cloud Event se a mensagem incluir Metadados de Evento de Nuvem. Tipo: boolean |
falso |
|
cloud-events-data-content-type (cloud-events-default-data-content-type) |
Configura o atributo 'datacontenttype' padrão do evento de nuvem de saída. Requer que 'cloud-events' seja definido como 'true'. Esse valor será usado se a mensagem não configurar o próprio atributo 'datacontenttype' Tipo: string |
falso |
|
cloud-events-data-schema (cloud-events-default-data-schema) |
Configura o atributo 'dataschema' padrão do evento de nuvem de saída. Requer que 'cloud-events' seja definido como 'true'. Esse valor será usado se a mensagem não configurar o próprio atributo 'dataschema' Tipo: string |
falso |
|
cloud-events-insert-timestamp (cloud-events-default-timestamp) |
Whether or not the connector should insert automatically the Type: boolean |
falso |
|
cloud-events-mode |
O modo Cloud Event ('estruturado' ou 'binário' (padrão)). Indica como são gravados os eventos de nuvem no registro de saída Tipo: string |
falso |
|
cloud-events-source (cloud-events-default-source) |
Configure o atributo 'source' padrão do evento de nuvem de saída. Requer que 'cloud-events' seja definido como 'true'. Esse valor será usado se a mensagem não configurar o próprio atributo 'source' Tipo: string |
falso |
|
cloud-events-subject (cloud-events-default-subject) |
Configure o atributo 'subject' padrão do evento de nuvem de saída. Requer que 'cloud-events' seja definido como 'true'. Esse valor será usado se a mensagem não configurar o próprio atributo 'subject' Tipo: string |
falso |
|
cloud-events-type (cloud-events-default-type) |
Configure o atributo 'type' padrão do evento de nuvem de saída. Requer que 'cloud-events' seja definido como 'true'. Esse valor será usado se a mensagem não configurar o próprio atributo 'type' Tipo: string |
falso |
|
health-enabled |
Se o relatório de integridade está habilitado (padrão) ou desabilitado Tipo: boolean |
falso |
|
health-readiness-enabled |
Se o relatório de integridade de prontidão está habilitado (padrão) ou desabilitado Tipo: boolean |
falso |
|
health-readiness-timeout |
deprecated - Durante a verificação de integridade de prontidão, o conector se conecta ao broker e recupera a lista de tópicos. Esse atributo especifica a duração máxima (em ms) para a recuperação. Se excedido, o canal é considerado não pronto. Preterido: use 'health-topic-verification-timeout' em vez disso. Tipo: long |
falso |
|
health-readiness-topic-verification |
deprecated - Se a verificação de prontidão deve verificar se os tópicos existem no broker. O padrão é false. Habilitá-lo requer uma conexão de administrador. Deprecated: use 'health-topic-verification-enabled' em vez disso. Tipo: boolean |
falso |
|
health-topic-verification-enabled |
Se a verificação de inicialização e prontidão deve verificar se os tópicos existem no broker. O padrão é false. Habilitá-lo requer uma conexão de cliente administrador. Tipo: boolean |
falso |
|
health-topic-verification-readiness-disabled |
Whether the topic verification is disabled for the readiness health check. Type: boolean |
falso |
|
health-topic-verification-startup-disabled |
Whether the topic verification is disabled for the startup health check. Type: boolean |
falso |
|
health-topic-verification-timeout |
Durante a verificação de integridade de inicialização e preparação, o conector se conecta ao agente e recupera a lista de tópicos. Esse atributo especifica a duração máxima (em ms) para a recuperação. Se excedido, o canal é considerado não pronto. Tipo: long |
falso |
|
interceptor-bean |
The name set in Type: string |
falso |
|
kafka-configuration |
Identificador de um bean CDI que fornece a configuração padrão do consumidor/produtor Kafka para esse canal. A configuração do canal ainda pode substituir qualquer atributo. O bean deve ter um tipo de Map<String, Object> e deve usar o qualificador @io.smallrye.common.annotation.Identifier para definir o identificador. Tipo: string |
falso |
|
key |
Uma chave a ser usada ao gravar o registro Tipo: string |
falso |
|
key-serialization-failure-handler |
O nome definido em '@Identifier' de um bean que implementa 'io.smallrye.reactive.messaging.kafka.SerializationFailureHandler'. Se definido, a falha de serialização que ocorre quando as chaves de serialização são delegadas a esse manipulador, que pode fornecer um valor de fallback. Tipo: string |
falso |
|
key.serializer |
O nome da classe do serializador usado para serializar a chave do registro Tipo: string |
falso |
|
lazy-client |
Se o cliente Kafka é criado preguiçosamente ou ansiosamente. Tipo: boolean |
falso |
|
max-inflight-messages |
O número máximo de mensagens a serem gravadas em Kafka simultaneamente. Ele limita o número de mensagens aguardando para serem escritas e reconhecidas pelo corretor. Você pode definir esse atributo como '0' remover o limite Tipo: long |
falso |
|
merge |
Se o conector deve permitir vários upstreams Tipo: boolean |
falso |
|
partition |
O id da partição de destino. -1 para permitir que o cliente determine a partição Tipo: int |
falso |
|
pooled-producer |
Whether to use a pool of Kafka producers for concurrent transactions. Each transaction scope acquires a producer from the pool, enabling concurrent exactly-once processing. Requires transactional.id to be set. Type: boolean |
falso |
|
pooled-producer.initial-pool-size |
Number of Kafka producers to pre-create in the pool at startup. Respects the lazy-client setting. Defaults to 0 (lazy creation). Type: int |
falso |
|
pooled-producer.max-pool-size |
Maximum number of Kafka producers in the pool. When all producers are in use and the pool is exhausted, an exception is thrown. Defaults to 10. Type: int |
falso |
|
propagate-headers |
Uma lista separada por vírgulas de cabeçalhos de registro de entrada a serem propagados para o registro de saída Tipo: string |
falso |
|
propagate-record-key |
Propagar a chave de registro de entrada para o registro de saída Tipo: boolean |
falso |
|
retries |
Se definido como um número positivo, o conector tentará reenviar qualquer registro que não tenha sido entregue com êxito (com um erro potencialmente transitório) até que o número de tentativas seja atingido. Se definido como 0, as novas tentativas serão desabilitadas. Se não estiver definido, o conector tentará reenviar qualquer registro que não tenha sido entregue (devido a um erro potencialmente transitório) durante um período de tempo configurado por 'delivery.timeout.ms'. Tipo: long |
falso |
|
topic |
O tópico Kafka consumido/populado. Se nem essa propriedade nem as propriedades 'topics' estiverem definidas, o nome do canal será usado Tipo: string |
falso |
|
tracing-enabled |
Se o rastreamento está habilitado (padrão) ou desabilitado Tipo: boolean |
falso |
|
value-serialization-failure-handler |
O nome definido em '@Identifier' de um bean que implementa 'io.smallrye.reactive.messaging.kafka.SerializationFailureHandler'. Se definido, a falha de serialização que ocorre quando os valores de serialização são delegados a esse manipulador, que pode fornecer um valor de fallback. Tipo: string |
falso |
|
value.serializer |
O nome da classe do serializador usado para serializar a carga útil Tipo: string |
verdadeiro |
|
waitForWriteCompletion |
Se o cliente espera que Kafka reconheça o registro escrito antes de reconhecer a mensagem Tipo: boolean |
falso |
|
28.3. Resolução de Configuração do Kafka
O Quarkus expõe todas as propriedades da aplicação relacionadas ao Kafka, prefixadas com kafka. ou KAFKA_ dentro de um mapa de configuração com o nome default-kafka-broker. Essa configuração é usada para estabelecer a conexão com o broker Kafka.
Além desta configuração predefinida, você pode configurar o nome do produtor Map utilizando o atributo kafka-configuration:
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.kafka-configuration=my-configurationNesse caso, o conector procura o Map associado ao nome my-configuration. Se kafka-configuration não estiver definido, será feita uma pesquisa opcional de um Map exposto com o nome do canal (my-channel no exemplo anterior).
@Produces
@ApplicationScoped
@Identifier("my-configuration")
Map<String, Object> outgoing() {
return Map.ofEntries(
Map.entry("value.serializer", ObjectMapperSerializer.class.getName())
);
}
Se kafka-configuration estiver definido e não for possível encontrar Map, a implantação falha.
|
Os valores dos atributos são resolvidos da seguinte forma:
-
o atributo é definido diretamente na configuração do canal (
mp.messaging.incoming.my-channel.attribute=value), -
se não estiver definido, o conector procura um
Mapcom o nome do canal ou okafka-configurationconfigurado (se definido) e o valor é obtido a partir desseMap -
Se o
Mapresolvido não contém o valor, é utilizado oMappadrão (exposto com o nomedefault-kafka-broker)
28.4. Configurar canais condicionalmente
Você pode configurar os canais usando um perfil específico. Assim, os canais só são configurados (e adicionados à aplicação) quando o perfil especificado é ativado.
Para conseguir isso, você precisa:
-
Prefixar as entradas
mp.messaging.[incoming|outgoing].$channelcom%my-profiletal como%my-profile.mp.messaging.[incoming|outgoing].$channel.key=value -
Utilizar o
@IfBuildProfile("my-profile")nos beans CDI que contêm anotações@Incoming(channel)e@Outgoing(channel)que só precisam ser ativadas quando o perfil é ativado.
Observe que as mensagens reativas verificam se o gráfico está completo. Portanto, ao usar essa configuração condicional, certifique-se de que a aplicação funcione com e sem o perfil ativado.
Note que esta abordagem também pode ser utilizada para alterar a configuração do canal com base num perfil.
29. Integrando com o Kafka - Padrões comuns
29.1. Escrever no Kafka a partir de um endpoint HTTP
Para enviar mensagens para o Kafka a partir de um endpoint HTTP, injete um Emitter (ou um MutinyEmitter) no seu endpoint:
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
@Path("/")
public class ResourceSendingToKafka {
@Channel("kafka") Emitter<String> emitter; (1)
@POST
@Produces(MediaType.TEXT_PLAIN)
public CompletionStage<Void> send(String payload) { (2)
return emitter.send(payload); (3)
}
}| 1 | Injete um Emitter<String> |
| 2 | O método HTTP recebe o conteúdo e devolve um CompletionStage concluído quando a mensagem é escrita no Kafka |
| 3 | Envie a mensagem para o Kafka, o método send devolve um CompletionStage |
O endpoint envia a conteúdo passado (de uma requisição HTTP POST) para o emissor. O canal do emissor é mapeado para um tópico do Kafka no arquivo application.properties:
mp.messaging.outgoing.kafka.connector=smallrye-kafka
mp.messaging.outgoing.kafka.topic=my-topicO endpoint retorna um CompletionStage indicando a natureza assíncrona do método. O método emitter.send retorna um CompletionStage<Void>. O future retornado é concluído quando a mensagem tiver sido gravada no Kafka. Se a gravação falhar, o CompletionStage retornado será concluído excepcionalmente.
Se o endpoint não devolver um CompletionStage, a resposta HTTP pode ser escrita antes de a mensagem ser enviada para o Kafka, e então as falhas não serão comunicadas ao usuário.
Se você precisa enviar um registro Kafka, use:
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
import io.smallrye.reactive.messaging.kafka.Record;
@Path("/")
public class ResourceSendingToKafka {
@Channel("kafka") Emitter<Record<String,String>> emitter; (1)
@POST
@Produces(MediaType.TEXT_PLAIN)
public CompletionStage<Void> send(String payload) {
return emitter.send(Record.of("my-key", payload)); (2)
}
}| 1 | Note a utilização de um Emitter<Record<K, V>> |
| 2 | Crie o registro usando Record.of(k, v) |
29.2. Persistindo mensagens Kafka com o Hibernate com Panache
Para persistir objetos recebidos do Kafka numa base de dados, você pode utilizar o Hibernate com o Panache.
| Se você estiver usando o Hibernate Reactive, veja Persistência de mensagens Kafka com o Hibernate Reativo. |
Vamos imaginar que você receba objetos Fruit. Para fins de simplificação, nossa classe Fruit é bastante simples:
package org.acme;
import jakarta.persistence.Entity;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
@Entity
public class Fruit extends PanacheEntity {
public String name;
}Para consumir instâncias do Fruit armazenadas num tópico do Kafka e mantê-las numa base de dados, você pode utilizar a seguinte abordagem:
package org.acme;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.transaction.Transactional;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import io.smallrye.common.annotation.Blocking;
@ApplicationScoped
public class FruitConsumer {
@Incoming("fruits") (1)
@Transactional (2)
public void persistFruits(Fruit fruit) { (3)
fruit.persist(); (4)
}
}| 1 | Configurando o canal de entrada. Este canal lê a partir do Kafka. |
| 2 | Como estamos escrevendo em um banco de dados, devemos estar em uma transação. Essa anotação inicia uma nova transação e a confirma quando o método retorna. O Quarkus considera automaticamente o método como blocante. De fato, a gravação em um banco de dados usando o Hibernate clássico é blocante. Portanto, o Quarkus chama o método em um thread de trabalho que pode ser bloqueado (e não em um thread de E/S). |
| 3 | O método recebe cada Fruit. Note que seria necessário um desserializador para reconstruir as instâncias Fruit a partir dos registros Kafka. |
| 4 | Persiste o objeto fruit recebido. |
Conforme mencionado em <4>, você precisa de um desserializador que possa criar um Fruit a partir do registro. Isso pode ser feito usando um desserializador Jackson:
package org.acme;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class FruitDeserializer extends ObjectMapperDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}A configuração associada seria:
mp.messaging.incoming.fruits.connector=smallrye-kafka
mp.messaging.incoming.fruits.value.deserializer=org.acme.FruitDeserializerConsulte Serialização via Jackson para mais detalhes sobre o uso do Jackson com o Kafka. Também é possível utilizar Avro.
29.3. Persistência de mensagens Kafka com o Hibernate Reativo
Para persistir objetos recebidos do Kafka numa base de dados, você pode utilizar o Hibernate Reativo com Panache.
Vamos imaginar que você receba objetos Fruit. Para fins de simplificação, nossa classe Fruit é bastante simples:
package org.acme;
import jakarta.persistence.Entity;
import io.quarkus.hibernate.reactive.panache.PanacheEntity; (1)
@Entity
public class Fruit extends PanacheEntity {
public String name;
}| 1 | Certifique-se de que utiliza a variante reativa |
Para consumir instâncias do Fruit armazenadas num tópico do Kafka e mantê-las numa base de dados, você pode utilizar a seguinte abordagem:
package org.acme;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.context.control.ActivateRequestContext;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import io.quarkus.hibernate.reactive.panache.Panache;
import io.smallrye.mutiny.Uni;
@ApplicationScoped
public class FruitStore {
@Inject
Mutiny.Session session; (1)
@Incoming("in")
@ActivateRequestContext (2)
public Uni<Void> consume(Fruit entity) {
return session.withTransaction(t -> { (3)
return entity.persistAndFlush() (4)
.replaceWithVoid(); (5)
}).onTermination().call(() -> session.close()); (6)
}
}| 1 | Injete a Session do Hibernate Reativo |
| 2 | As APIs Session e Panache do Hibernate Reativo exigem um Contexto de Requisição CDI ativo. A anotação @ActivateRequestContext cria um novo contexto de requisição e o destrói quando o Uni retorno do método é concluído. Se o Panache não for usado, o Mutiny.SessionFactory poderá ser injetado e usado de forma semelhante, sem a necessidade de ativar o contexto de requisição ou fechar a sessão manualmente. |
| 3 | Solicita uma nova transação. A transação é concluída quando a ação passada é concluída. |
| 4 | Persiste a entidade. Devolve um Uni<Fruit>. |
| 5 | Troque de volta para um Uni<Void>. |
| 6 | Feche a sessão - isto é, fechar a conexão com a base de dados. A conexão pode então ser reciclada. |
Diferentemente do Hibernate clássico, você não pode usar @Transactional. Em vez disso, usamos session.withTransaction e persistimos nossa entidade. O map é usado para retornar um Uni<Void> e não um Uni<Fruit>.
Você precisa de um desserializador que possa criar um Fruit a partir do registro. Isso pode ser feito usando um desserializador Jackson:
package org.acme;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class FruitDeserializer extends ObjectMapperDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}A configuração associada seria:
mp.messaging.incoming.fruits.connector=smallrye-kafka
mp.messaging.incoming.fruits.value.deserializer=org.acme.FruitDeserializerConsulte Serialização via Jackson para mais detalhes sobre o uso do Jackson com o Kafka. Também é possível utilizar Avro.
29.4. Escrevendo entidades gerenciadas pelo Hibernate no Kafka
Vamos imaginar o seguinte processo:
-
VocêrRecebe uma requisição HTTP com um conteúdo,
-
Você uma instância de entidade Hibernate a partir deste conteúdo,
-
Você persiste essa entidade numa base de dados,
-
Você envia a entidade para um tópico do Kafka
| Se você estiver usando Hibernate Reactive, veja Escrevendo entidades gerenciadas pelo Hibernate Reativo no Kafka. |
Como gravamos em um banco de dados, precisamos executar esse método em uma transação.
No entanto, o envio da entidade para o Kafka ocorre de forma assíncrona.
Podemos conseguir isso usando .sendAndAwait() ou .sendAndForget() no site MutinyEmitter , ou .send().toCompletableFuture().join() no Emitter .
Para implementar este processo, é necessária a seguinte abordagem:
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.transaction.Transactional;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.smallrye.reactive.messaging.MutinyEmitter;
@Path("/")
public class ResourceSendingToKafka {
@Channel("kafka") MutinyEmitter<Fruit> emitter;
@POST
@Path("/fruits")
@Transactional (1)
public void storeAndSendToKafka(Fruit fruit) { (2)
fruit.persist();
emitter.sendAndAwait(new FruitDto(fruit)); (3)
}
}| 1 | Como estamos escrevendo para a base de dados, certifique-se de que executamos dentro de uma transação |
| 2 | O método recebe a instância da fruta para persistir. |
| 3 | Envolva a entidade gerenciada em um objeto de transferência de dados e envie-a para o Kafka. Isso garante que a entidade gerenciada não seja afetada pela serialização do Kafka. Em seguida, aguarde a conclusão da operação antes de retornar. |
Você não deve retornar CompletionStage ou Uni ao usar @Transactional , pois todas as confirmações de transação ocorrerão em um único thread, o que afeta o desempenho.
|
29.5. Escrevendo entidades gerenciadas pelo Hibernate Reativo no Kafka
Para enviar para entidades Kafka gerenciadas pelo Hibernate Reativo, recomendamos usar:
-
Quarkus REST para servir requisições HTTP
-
Um
MutinyEmitterpara enviar mensagens para um canal, para que possa ser facilmente integrado com a API do Mutiny exposta pelo Hibernate Reativo ou Hibernate Reativo com Panache.
O exemplo a seguir demonstra como receber um conteúdo, armazená-lo na base de dados utilizando o Hibernate Reativo com Panache e enviar a entidade persistente para o Kafka:
package org.acme;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.quarkus.hibernate.reactive.panache.Panache;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.MutinyEmitter;
@Path("/")
public class ReactiveGreetingResource {
@Channel("kafka") MutinyEmitter<Fruit> emitter; (1)
@POST
@Path("/fruits")
public Uni<Void> sendToKafka(Fruit fruit) { (2)
return Panache.withTransaction(() -> (3)
fruit.<Fruit>persist()
)
.chain(f -> emitter.send(f)); (4)
}
}| 1 | Injete um MutinyEmitter que expõe uma API do Mutiny. Ele simplifica a integração com a API do Mutiny exposta pelo Hibernate Reativo com Panache. |
| 2 | O método HTTP que recebe o conteúdo devolve um Uni<Void>. A resposta HTTP é escrita quando a operação é concluída (a entidade é persistida e escrita no Kafka). |
| 3 | Temos de escrever a entidade na base de dados numa transação. |
| 4 | Uma vez concluída a operação de persistência, enviamos a entidade para o Kafka. O método send devolve um Uni<Void>. |
29.6. Transmitindo tópicos do Kafka como eventos enviados pelo servidor
A transmissão de um tópico do Kafka como eventos enviados pelo servidor (SSE) é simples:
-
Você injeta o canal que representa o tópico Kafka no seu endpoint HTTP
-
Você devolve esse canal como
PublisherouMultia partir do método HTTP
O código seguinte apresenta um exemplo:
@Channel("fruits")
Multi<Fruit> fruits;
@GET
@Produces(MediaType.SERVER_SENT_EVENTS)
public Multi<Fruit> stream() {
return fruits;
}Alguns ambientes cortam a conexão SSE quando não há atividade suficiente. A solução alternativa consiste em enviar mensagens de ping (ou objetos vazios) periodicamente.
@Channel("fruits")
Multi<Fruit> fruits;
@Inject
ObjectMapper mapper;
@GET
@Produces(MediaType.SERVER_SENT_EVENTS)
public Multi<String> stream() {
return Multi.createBy().merging()
.streams(
fruits.map(this::toJson),
emitAPeriodicPing()
);
}
Multi<String> emitAPeriodicPing() {
return Multi.createFrom().ticks().every(Duration.ofSeconds(10))
.onItem().transform(x -> "{}");
}
private String toJson(Fruit f) {
try {
return mapper.writeValueAsString(f);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}A solução alternativa é um pouco mais complexa, pois além de enviar os fruits provenientes do Kafka, precisamos enviar pings periodicamente. Para isso, mesclamos o fluxo proveniente do Kafka e um fluxo periódico que emite {} a cada 10 segundos.
29.7. Encadeando Transações do Kafka com transações Reativas do Hibernate
Ao encadear uma transação do Kafka com uma transação reativa do Hibernate, é possível enviar registros para uma transação do Kafka, realizar atualizações do banco de dados e confirmar a transação do Kafka somente se a transação do banco de dados for bem-sucedida.
O exemplo a seguir demonstra isso:
-
Receber um payload ao servir requisições HTTP usando Quarkus REST,
-
Limite a simultaneidade desse ponto de extremidade HTTP usando o SmallRye Fault Tolerance,
-
Inicia uma transação Kafka e envia o conteúdo para o registro Kafka,
-
Armazenaoa conteúdo na base de dados utilizando Hibernate Reativo com Panache,
-
Confirma a transação Kafka apenas se a entidade for persistida com êxito.
package org.acme;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.faulttolerance.Bulkhead;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.hibernate.reactive.mutiny.Mutiny;
import io.quarkus.hibernate.reactive.panache.Panache;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Fruit> kafkaTx; (1)
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1) (2)
public Uni<Void> post(Fruit fruit) { (3)
return kafkaTx.withTransaction(emitter -> { (4)
emitter.send(fruit); (5)
return Panache.withTransaction(() -> { (6)
return fruit.<Fruit>persist(); (7)
});
}).replaceWithVoid();
}
}| 1 | Injeta um KafkaTransactions que expõe uma API do Mutiny. Isso permite a integração com a API do Mutiny exposta pelo Hibernate Reativo com Panache. |
| 2 | Limita a concorrência do endpoint HTTP a "1", impedindo o início de várias transações num determinado momento. |
| 3 | O método HTTP que recebe o conteúdo devolve um Uni<Void>. A resposta HTTP é escrita quando a operação é concluída (a entidade é persistida e a transação Kafka é confirmada). |
| 4 | Inicia uma transação Kafka. |
| 5 | Envia o contéudo para o Kafka dentro da transação Kafka. |
| 6 | Persiste a entidade na base de dados numa transação reativa do Hibernate. |
| 7 | Quando a operação de persistência for concluída e não houver erros, a transação do Kafka será confirmada. O resultado é omitido e retornado como resposta HTTP. |
No exemplo anterior, a transação do banco de dados (interna) será confirmada seguida pela transação do Kafka (externa). Se você quiser confirmar a transação do Kafka primeiro e a transação do banco de dados depois, precisará aninhá-las na ordem inversa.
O próximo exemplo demonstra isso utilizando a API reativa do Hibernate (sem o Panache):
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.faulttolerance.Bulkhead;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.hibernate.reactive.mutiny.Mutiny;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
import io.vertx.mutiny.core.Context;
import io.vertx.mutiny.core.Vertx;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Fruit> kafkaTx;
@Inject Mutiny.SessionFactory sf; (1)
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1)
public Uni<Void> post(Fruit fruit) {
return sf.withTransaction(session -> (2)
kafkaTx.withTransaction(emitter -> (3)
session.persist(fruit).invoke(() -> emitter.send(fruit)) (4)
));
}
}| 1 | Injeta o SessionFactory do Hibernate Reativo. |
| 2 | Inicia uma transação Reativa do Hibernate. |
| 3 | Inicia uma transação Kafka. |
| 4 | Persiste o conteúdo e envia a entidade para o Kafka. |
Como alternativa, você pode usar a anotação @WithTransaction para iniciar uma transação e confirmá-la quando o método retornar:
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.faulttolerance.Bulkhead;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.quarkus.hibernate.reactive.panache.common.WithTransaction;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Fruit> kafkaTx;
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1)
@WithTransaction (1)
public Uni<Void> post(Fruit fruit) {
return kafkaTx.withTransaction(emitter -> (2)
fruit.persist().invoke(() -> emitter.send(fruit)) (3)
);
}
}| 1 | Iniciar uma transação do Hibernate Reactive e confirmá-la quando o método retornar. |
| 2 | Inicia uma transação Kafka. |
| 3 | Persiste o conteúdo e envia a entidade para o Kafka. |
29.8. Encadeamento de transações Kafka com transações ORM do Hibernate
Embora o site KafkaTransactions forneça uma API reativa sobre o Mutiny para gerenciar transações do Kafka,
você ainda pode encadear transações do Kafka com transações ORM do Hibernate bloqueadas.
import jakarta.transaction.Transactional;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.quarkus.logging.Log;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Pet> emitter;
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1)
@Transactional (1)
public void post(Fruit fruit) {
emitter.withTransaction(e -> { (2)
// if id is attributed by the database, will need to flush to get it
// fruit.persistAndFlush();
fruit.persist(); (3)
Log.infov("Persisted fruit {0}", p);
e.send(p); (4)
return Uni.createFrom().voidItem();
}).await().indefinitely(); (5)
}
}| 1 | Inicia uma transação ORM do Hibernate. A transação é confirmada quando o método retorna. |
| 2 | Inicia uma transação Kafka. |
| 3 | Persistir o payload. |
| 4 | Enviar a entidade para o Kafka dentro da transação do Kafka. |
| 5 | Aguarde o retorno de Uni para que a transação do Kafka seja concluída. |
30. Registrando
Para reduzir a quantidade de registros escritos pelo cliente Kafka, o Quarkus define o nível das seguintes categorias de registros para WARNING:
-
org.apache.kafka.clients -
org.apache.kafka.common.utils -
org.apache.kafka.common.metrics
É possível substituir a configuração adicionando as seguintes linhas ao arquivo application.properties:
quarkus.log.category."org.apache.kafka.clients".level=INFO
quarkus.log.category."org.apache.kafka.common.utils".level=INFO
quarkus.log.category."org.apache.kafka.common.metrics".level=INFO31. Conectando a clusters do Kafka Gerenciados
Esta seção explica como conectar aos notórios Kafka Cloud Services.
31.1. Hubs de Eventos do Azure
O Hub de Eventos do Azure fornece um endpoint compatível com o Apache Kafka.
| Os Hubs de Eventos do Azure para Kafka não estão disponíveis na camada básica. Você precisa de pelo menos a camada padrão para usar o Kafka. Consulte Preços do Hubs de Eventos do Azure para ver as outras opções. |
Para se conectar ao Hub de Eventos do Azure, utilizando o protocolo Kafka com TLS, você precisa da seguinte configuração:
kafka.bootstrap.servers=my-event-hub.servicebus.windows.net:9093 (1)
kafka.security.protocol=SASL_SSL
kafka.sasl.mechanism=PLAIN
kafka.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \ (2)
username="$ConnectionString" \ (3)
password="<YOUR.EVENTHUBS.CONNECTION.STRING>"; (4)| 1 | A porta é 9093. |
| 2 | Você precisa usar o JAAS PlainLoginModule. |
| 3 | O nome de usuário é a string $ConnectionString. |
| 4 | A cadeia de conexão do Hub de Eventos fornecida pelo Azure. |
Substitua <YOUR.EVENTHUBS.CONNECTION.STRING> pela cadeia de conexão do seu namespace do Hub de Eventos. Para obter instruções sobre como obter a cadeia de conexão, consulte Obter uma cadeia de conexão dos Hubs de Evento. O resultado seria algo como:
kafka.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="$ConnectionString" \
password="Endpoint=sb://my-event-hub.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=XXXXXXXXXXXXXXXX";Esta configuração pode ser global (como acima), ou definida na configuração do canal:
mp.messaging.incoming.$channel.bootstrap.servers=my-event-hub.servicebus.windows.net:9093
mp.messaging.incoming.$channel.security.protocol=SASL_SSL
mp.messaging.incoming.$channel.sasl.mechanism=PLAIN
mp.messaging.incoming.$channel.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="$ConnectionString" \
password="Endpoint=sb://my-event-hub.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=...";32. Indo mais longe
Este guia mostrou como você pode interagir com o Kafka usando o Quarkus. Ele utiliza a Mensageria Quarkus para construir aplicações de streaming de dados.
Se quiser ir mais longe, consulte a documentação da Mensageria Reativa do SmallRye, a implementação utilizada no Quarkus.