Introdução ao Reativo
Reativo é um conjunto de princípios para criar aplicações e sistemas robustos, eficientes e concorrentes. Esses princípios permitem lidar com mais carga do que as abordagens tradicionais e, ao mesmo tempo, usar os recursos (CPU e memória) de forma mais eficiente e reagir a falhas com elegância.
O Quarkus é um framework Reativo . Desde o início, a Reatividade tem sido um princípio essencial da arquitetura do Quarkus. Ela inclui muitos recursos reativos e oferece um amplo ecossistema.
Este guia não é um artigo detalhado sobre o que é Reativo e como o Quarkus permite arquiteturas reativas. Se quiser ler mais sobre esses tópicos, consulte o guia de Arquitetura Reativa , que fornece uma visão geral do ecossistema reativo do Quarkus.
Neste guia, vamos te introduzir a alguns recursos reativos do Quarkus. Vamos implementar um aplicativo CRUD simples. No entanto, diferentemente do guia do Hibernate com Panache , ele usa os recursos reativos do Quarkus.
Este guia vai ajudá-lo a:
-
Criar uma aplicação CRUD reativa com o Quarkus
-
Utilizar o Hibernate Reactive com o Panache para interagir com uma base de dados de forma reativa
-
Using Quarkus REST (formerly RESTEasy Reactive) to implement HTTP API while enforcing the reactive principle
-
Empacotar e Executar a aplicação
Pré-requisitos
Para concluir este guia, você precisa:
-
Cerca de 15 minutos
-
Um IDE
-
JDK 17+ instalado com
JAVA_HOMEconfigurado corretamente -
Apache Maven 3.9.16
-
Opcionalmente, o Quarkus CLI se você quiser usá-lo
-
Opcionalmente, Mandrel ou GraalVM instalado e configurado apropriadamente se você quiser criar um executável nativo (ou Docker se você usar uma compilação de contêiner nativo)
Verify that Maven is using the Java version you expect.
If you have multiple JDKs installed, make sure Maven is using the expected one.
You can verify which JDK Maven uses by running mvn --version.
|
Imperativo vs. Reativo: uma questão de threads
Conforme mencionado acima, neste guia, vamos implementar um aplicativo CRUD reativo. Mas você pode se perguntar quais são as diferenças e os benefícios em comparação com o modelo tradicional e imperativo.
Para entender melhor o contraste, precisamos explicar a diferença entre os modelos de execução reativo e imperativo. É essencial compreender que o Reativo não é apenas um modelo de execução diferente, mas essa distinção é necessária para entender este guia.
Na abordagem tradicional e imperativa, os frameworks atribuem um thread para tratar a requisição. Assim, todo o processamento da requisição é executado nesse thread de trabalho. Esse modelo não escala muito bem. De fato, para lidar com várias requisições concorrentes, são necessários vários threads e, portanto, a concorrência da aplicação é limitada pelo número de threads. Além disso, esses threads são bloqueados assim que o código interage com os serviços remotos. Portanto, isso leva ao uso ineficiente dos recursos, pois você pode precisar de mais threads, e cada thread, como são mapeados para threads do sistema operacional, tem um custo em termos de memória e CPU.
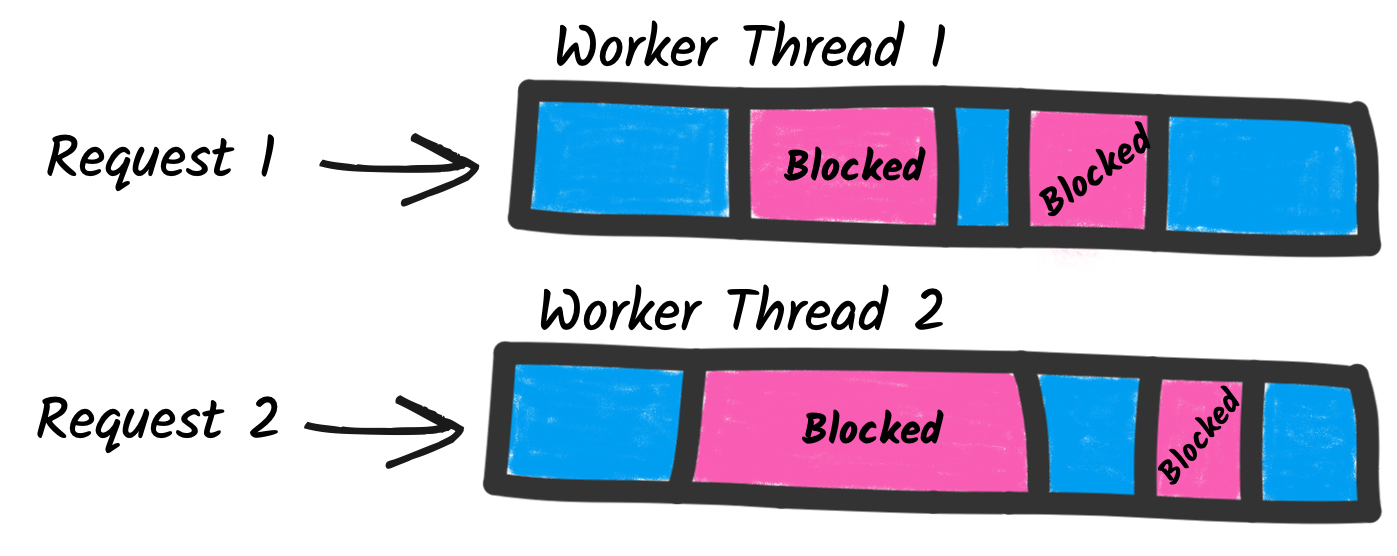
Por outro lado, o modelo reativo se baseia em E/S sem bloqueio e em um modelo de execução diferente. A E/S sem bloqueio oferece uma maneira eficiente de lidar com E/S concorrente. Um número mínimo de threads, chamados threads de E/S, pode lidar com muitas E/S concorrentes. Com esse modelo, o processamento de solicitações não é delegado a um thread de trabalho, mas usa esses threads de E/S diretamente, o que economiza memória e CPU, pois não há necessidade de criar threads de trabalho para lidar com as requisições. Ele também melhora a concorrência, pois remove a restrição do número de threads. Por fim, ele também melhora o tempo de resposta, pois reduz o número de trocas de thread.
Do estilo sequencial ao estilo de continuação
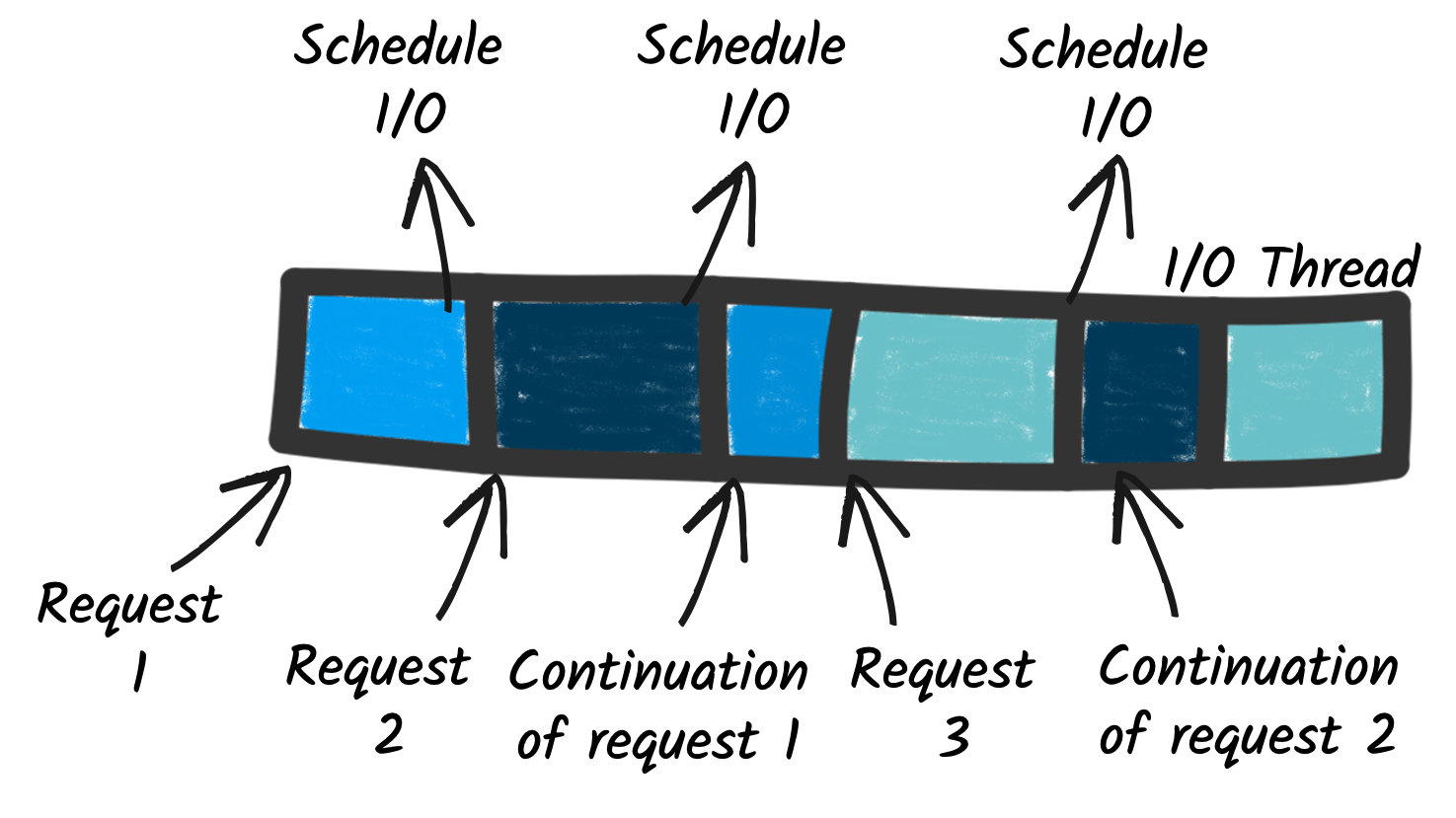
Portanto, com o modelo de execução reativa, as requisições são processadas usando threads de E/S. Mas isso não é tudo. Um thread de E/S pode lidar com várias solicitações concorrentes. Como? Aqui está o truque e uma das diferenças mais significativas entre o reativo e o imperativo.
Quando o processamento de uma requisição exige a interação com um serviço remoto, como uma API HTTP ou um banco de dados, ele não bloqueia a execução enquanto aguarda a resposta. Em vez disso, ele agenda a operação de E/S e anexa uma continuação, ou seja, o código restante do processamento da requisição. Essa continuação pode ser passada como um retorno de chamada (uma função invocada com o resultado de E/S) ou usar construções mais avançadas, como programação reativa ou corrotinas. Independentemente de como a continuação é expressa, o aspecto essencial é a liberação do thread de E/S e, como consequência, o fato de que esse thread pode ser usado para processar outra requisição. Quando a E/S programada é concluída, o thread de E/S executa a continuação e o processamento da requisição pendente continua.
Portanto, ao contrário do modelo imperativo, em que a E/S bloqueia a execução, o reativo muda para um design baseado em continuação, em que os threads de E/S são liberados e a continuação é invocada quando as E/S são concluídas. Como resultado, o thread de E/S pode lidar com várias requisições concorrentes, melhorando a concorrência geral da aplicação.
Mas há um problema. Precisamos de uma maneira de escrever código de passagem de continuação. Há muitas maneiras de fazer isso. No Quarkus, nós propomos:
-
Mutiny - uma biblioteca de programação reativa intuitiva e orientada a eventos
-
Corrotinas Kotlin - uma forma de escrever código assíncrono de forma sequencial
Neste guia, usaremos o Mutiny. Para saber mais sobre o Mutiny, consulte a documentação do Mutiny .
| O Projeto Loom chegará ao JDK em breve e propõe um modelo virtual baseado em thread. A arquitetura Quarkus está pronta para suportar o Loom assim que ele estiver disponível globalmente. |
Criando a aplicação Reactive Fruits
Com isto em mente, vamos ver como podemos desenvolver uma aplicação CRUD com o Quarkus, que utilizará o thread de E/S para tratar as requisições HTTP, interagir com uma base de dados, processar o resultado e escrever a resposta HTTP; em outras palavras: uma aplicação CRUD reativa.
Embora recomendemos que siga as instruções passo a passo, você pode encontrar a solução final em https://github.com/quarkusio/quarkus-quickstarts/tree/main/hibernate-reactive-panache-quickstart.
Primeiro, vá para code.quarkus.io e selecione as seguintes extensões:
-
Quarkus REST Jackson
-
Hibernate Reactive with Panache
-
Reactive PostgreSQL client
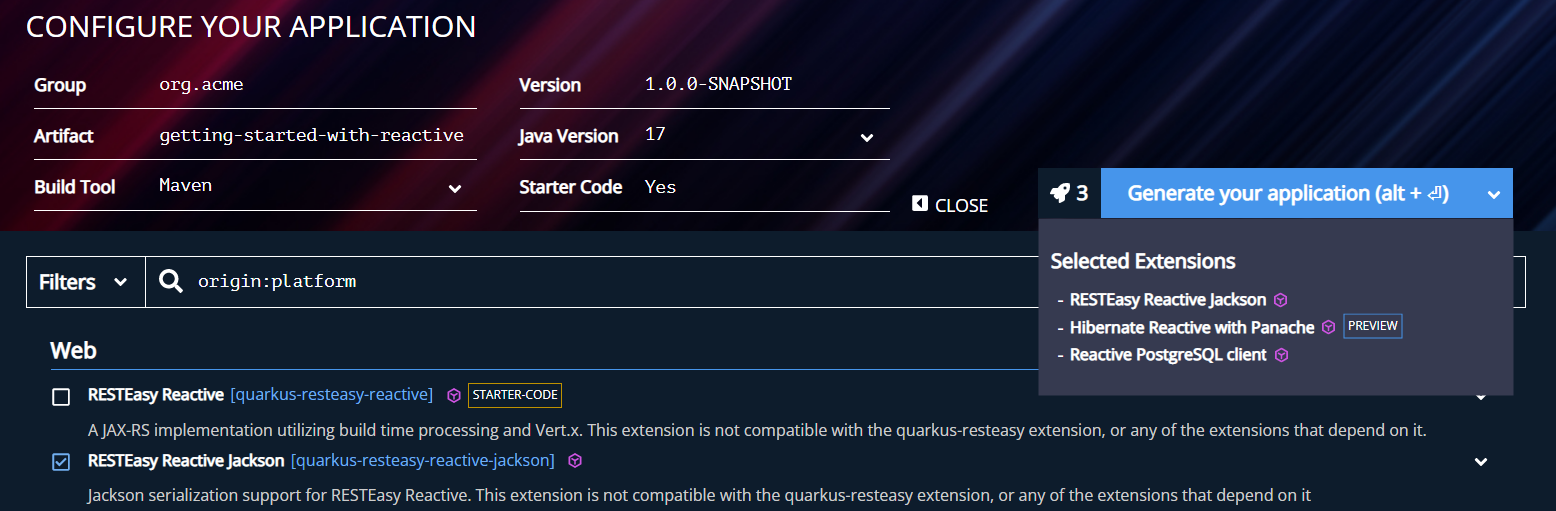
A última extensão é o driver de banco de dados reativo para o PostgreSQL. O Hibernate Reativo usa esse driver para interagir com o banco de dados sem bloquear o thread do chamador.
Uma vez selecionadas, clique em "Generate your application", baixe o ficheiro zip, descompacte-o e abra o código no seu IDE favorito.
Entidade Panache Reativa
Vamos começar com a entidade Fruit. Crie o arquivo src/main/java/org/acme/hibernate/orm/panache/Fruit.java com o seguinte conteúdo:
package org.acme.hibernate.orm.panache;
import jakarta.persistence.Cacheable;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import io.quarkus.hibernate.reactive.panache.PanacheEntity; (1)
@Entity
@Cacheable
public class Fruit extends PanacheEntity {
@Column(length = 40, unique = true)
public String name;
}| 1 | Certifique-se de importar a variante reativa de PanacheEntity. |
Essa classe representa Fruits . É uma entidade simples com um único campo ( name ). Observe que ela usa io.quarkus.hibernate.reactive.panache.PanacheEntity , a variante reativa de PanacheEntity . Portanto, por debaixo dos panos, o Hibernate usa o modelo de execução que descrevemos acima. Ele interage com o banco de dados sem bloquear o thread. Além disso, esse PanacheEntity reativo propõe uma API reativa. Usaremos essa API para implementar o endpoint REST.
Antes de prosseguir, abra o arquivo src/main/resources/application.properties e adicione:
quarkus.datasource.db-kind=postgresql
quarkus.hibernate-orm.schema-management.strategy=drop-and-createEle instrui a aplicação a utilizar o PostgreSQL para a base de dados e para tratar da geração do esquema da base de dados.
No mesmo diretório, crie um arquivo import.sql, que insere algumas frutas, para não começarmos com uma base de dados vazia no modo de desenvolvimento:
INSERT INTO fruit(id, name) VALUES (1, 'Cherry');
INSERT INTO fruit(id, name) VALUES (2, 'Apple');
INSERT INTO fruit(id, name) VALUES (3, 'Banana');
ALTER SEQUENCE fruit_seq RESTART WITH 4;Em um terminal, inicie a aplicação no modo de desenvolvimento usando: ./mvnw quarkus:dev . O Quarkus inicia automaticamente uma instância de banco de dados para você e configura a aplicação. Agora só precisamos implementar o endpoint HTTP.
Recurso Reativo
Como a interação com o banco de dados é assíncrona e sem bloqueio, precisamos usar construções assíncronas para implementar nosso recurso HTTP. O Quarkus usa o Mutiny como seu modelo central de programação reativa. Portanto, ele suporta o retorno de tipos Mutiny ( Uni e Multi ) a partir de endpoints HTTP. Além disso, nossa entidade Fruit Panache expõe métodos que usam esses tipos, portanto, só precisamos implementar a cola .
Crie o arquivo src/main/java/org/acme/hibernate/orm/panache/FruitResource.java com o seguinte conteúdo:
package org.acme.hibernate.orm.panache;
import java.util.List;
import io.quarkus.panache.common.Sort;
import io.smallrye.mutiny.Uni;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.ws.rs.Path;
@Path("/fruits")
@ApplicationScoped
public class FruitResource {
}Vamos começar com o método getAll . O método getAll retorna todas as frutas armazenadas no banco de dados. Em FruitResource , adicione o seguinte código:
@GET
public Uni<List<Fruit>> get() {
return Fruit.listAll(Sort.by("name"));
}Abra http://localhost:8080/fruits para invocar este método:
[{"id":2,"name":"Apple"},{"id":3,"name":"Banana"},{"id":1,"name":"Cherry"},{"id":4,"name":"peach"}]We get the expected JSON array. Quarkus REST automatically maps the list into a JSON Array, except if instructed otherwise.
Observe o tipo de retorno; ele retorna um Uni de List<Fruit> . Uni é um tipo assíncrono. É um pouco como um future. É um espaço reservado que obterá seu valor (item) mais tarde. Quando ele recebe o item (o Mutiny diz que ele emite seu item), você pode anexar algum comportamento. É assim que expressamos a continuação: obter um uni e, quando o uni emitir seu item, executar o restante do processamento.
Os desenvolvedores reativos podem se perguntar por que não podemos retornar um fluxo de frutas diretamente. Isso tende a ser uma má ideia quando se lida com um banco de dados. Os bancos de dados relacionais não lidam bem com o streaming. É um problema de protocolos não projetados para esse caso de uso. Portanto, para transmitir linhas do banco de dados, você precisa manter uma conexão (e, às vezes, uma transação) aberta até que todas as linhas sejam consumidas. Se os consumidores forem lentos, você quebra a regra de ouro dos bancos de dados: não mantenha as conexões por muito tempo. Na verdade, o número de conexões é bastante baixo, e ter consumidores mantendo-as por muito tempo reduzirá drasticamente a concorrência da sua aplicação. Portanto, quando possível, use um Uni<List<T>> e carregue o conteúdo. Se você tiver um grande conjunto de resultados, implemente a paginação.
|
Vamos continuar a nossa API com getSingle:
@GET
@Path("/{id}")
public Uni<Fruit> getSingle(Long id) {
return Fruit.findById(id);
}Nesse caso, usamos Fruit.findById para recuperar a fruta. Ele retorna um Uni , que será concluído quando o banco de dados tiver recuperado a linha.
O método create permite acrescentar uma nova fruta na base de dados:
@POST
public Uni<RestResponse<Fruit>> create(Fruit fruit) {
return Panache.withTransaction(fruit::persist).replaceWith(RestResponse.status(CREATED, fruit));
}O código é um pouco mais complexo. Para gravar em um banco de dados, precisamos de uma transação; portanto, usamos Panache.withTransaction para obter uma transação (de forma assíncrona) e chamamos o método persist . O método persist retorna um Uni que emite o resultado da inserção da fruta no banco de dados. Após a conclusão da inserção (que desempenha o papel da continuação), criamos uma resposta HTTP 201 CREATED .
Se tiver curl na sua máquina, você pode testar o endpoint utilizando:
> curl --header "Content-Type: application/json" \
--request POST \
--data '{"name":"peach"}' \
http://localhost:8080/fruitsSeguindo as mesmas ideias, pode implementar os outros métodos CRUD.
Testando e Executando
O teste de uma aplicação reativa é semelhante ao teste de uma aplicação não reativa: use o endpoint HTTP e verifique as respostas HTTP. O fato de a aplicação ser reativa não muda nada.
Em FruitsEndpointTest.java você pode ver como o teste da aplicação da fruta pode ser implementado.
O empacotamento e a execução da aplicação também não mudam.
Você pode utilizar o seguinte comando como de costume:
quarkus build./mvnw install./gradlew buildou para construir um executável nativo:
quarkus build --native./mvnw install -Dnative./gradlew build -Dquarkus.native.enabled=trueTambém é possível empacotar a aplicação em um container.
Para executar a aplicação, não se esqueça de iniciar uma base de dados e de fornecer a configuração à sua aplicação.
Por exemplo, pode utilizar o Docker para executar a sua base de dados:
docker run -it --rm=true \
--name postgres-quarkus -e POSTGRES_USER=quarkus \
-e POSTGRES_PASSWORD=quarkus -e POSTGRES_DB=fruits \
-p 5432:5432 docker.io/library/postgres:18Em seguida, inicie a aplicação utilizando:
java \
-Dquarkus.datasource.reactive.url=postgresql://localhost/fruits \
-Dquarkus.datasource.username=quarkus \
-Dquarkus.datasource.password=quarkus \
-jar target/quarkus-app/quarkus-run.jarOu, se tiver empacotado a sua aplicação como executável nativo, utilize:
./target/getting-started-with-reactive-runner \
-Dquarkus.datasource.reactive.url=postgresql://localhost/fruits \
-Dquarkus.datasource.username=quarkus \
-Dquarkus.datasource.password=quarkusOs parâmetros passados para a aplicação estão descritos no guia de fontes de dados. Há outras maneiras de configurar a aplicação - consulte o guia de configuração para ter uma visão geral das possibilidades (como variável de ambiente, arquivos .env e assim por diante).