Kubernetes Service Discovery and Selection with Stork
By

As we already described in the previous post, SmallRye Stork is a service discovery and client-side load-balancing framework that brings out-of-the-box integration with Kubernetes, among others. This post will explain this integration, how to configure Stork in a client-side microservice, and how it differs from the classic Kubernetes service discovery and load-balancing.
This post has been updated to use the quarkus. prefix when configuring stork properties. This prefix is required since Quarkus 2.8.
|
Kubernetes service discovery and load balancing
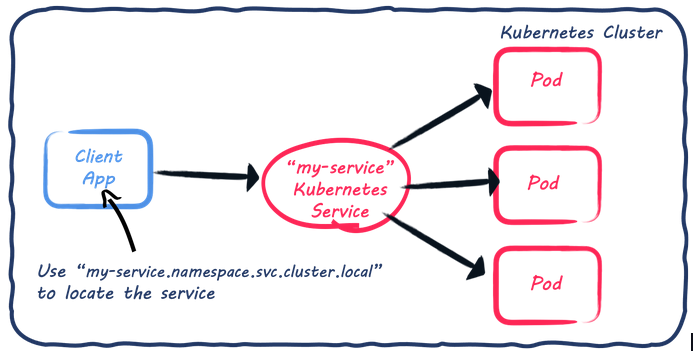
Kubernetes has built-in service discovery and load balancing.
Let’s imagine you have an application deployed in Kubernetes and exposing an HTTP API. You declare a Kubernetes service that delegates the calls to your application. This service acts as a proxy in front of a set of pods (often application replicas). When another application calls our HTTP API, it uses DNS to locate the Kubernetes service and uses the resolved address. It’s important to understand that it does not locate and call the application instance but the Kubernetes service. This service then delegates the call to the actual application and implements a round-robin when there are multiple replicas.
What does Stork bring for Kubernetes?
Even though Kubernetes has built-in support for service discovery, sometimes we need more flexibility in the service instance selection. As we have seen, the Kubernetes service implements a round-robin. With Stork, you can customize the selection.
Unlike in the previous example, Stork does not use DNS to locate the Kubernetes service. It uses the Kubernetes API to retrieve the set of pods behind a Kubernetes service. Then, you can apply any Stork service selection or even implement your own.
The following figure depicts the architecture and how Stork locates and selects the service instance.
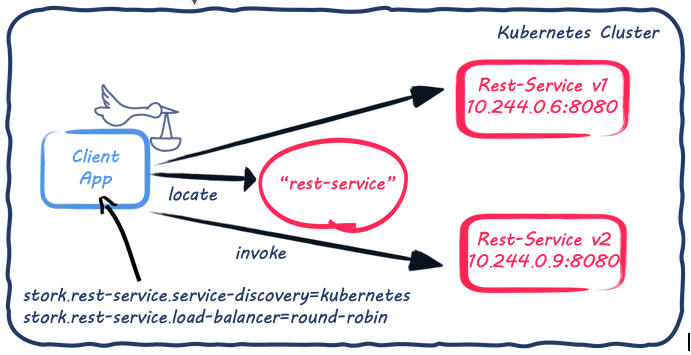
As shown in the architecture above, the Kubernetes rest-service is backed by two pods. While classic Kubernetes service discovery would ensure that requests to the rest-service are load-balanced across these two pods, Stork retrieves the pods' addresses directly. Thus it can handle the service selection (using a round-robin for now).
Note that while applications using Stork do not use the Kubernetes service delegation, they still require a Kubernetes service to discover the backed pods. So, it does not change your Kubernetes deployment.
Configuring and Using Stork Kubernetes Service Discovery
On the client-side, our Quarkus application uses the REST Client Reactive to interact with the REST API exposed by the rest-service. The Client app uses Stork to discover the rest-service instances. The easiest way to enable Stork is to add the corresponding Jar to the classpath of your project:
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>stork-service-discovery-kubernetes</artifactId>
</dependency>With Stork and the Stork Kubernetes Service Discovery on the classpath, we need to tell Stork how to locate and select the service. To achieve this, we just add stork.[service-name].[kebab-cased-property-name] into the Quarkus application configuration. In our case, to configure the rest-service and indicate to Stork that it should use Kubernetes, we add:
quarkus.stork.rest-service.service-discovery.type=kubernetes
quarkus.stork.rest-service.service-discovery.k8s-namespace=my-namespaceNote that you can also configure them via annotations, check the @ServiceDiscoveryType and @ServiceDiscoveryAttribute annotations.
We also can limit the service lookup to our namespace. We can also use the all value to look for services in all namespaces.
There are a few more properties that we can configure to tune the service discovery:
| Property | Descrição |
|---|---|
quarkus.stork.service-name.service-discovery.k8s-host |
The Kubernetes API url |
quarkus.stork.service-name.service-discovery.application |
The name of the target application |
quarkus.stork.service-name.service-discovery.refresh-period |
Service discovery cache refresh period |
quarkus.stork.service-name.service-discovery.secure |
Use a secure connection (e.g. HTTPS) |
That’s how easy it is to have Stork Kubernetes service discovery.
Once Stork is configured, we need to configure the REST Client to use it. It can be done in the @RegisterRestClient annotated interface by adding the baseUri attribute with the stork:// scheme:
@Path("/test")
@RegisterRestClient(baseUri = "stork://rest-service")
public interface Client {
@GET
@Path("/")
Uni<String> get();
}Customizing the service selection
Now that the service is located, we need to select the best instance. For example, you can use the least-response-time load-balancer implementation. This selection strategy monitors the interactions and selects the fastest instance to improve the response time.
To achieve this, you need to add the load-balancer implementation on your classpath:
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>smallrye-stork-load-balancer-response-time</artifactId>
</dependency>Then, in the application configuration, add:
quarkus.stork.my-service.load-balancer.type=least-response-timeObviously, you can pick any load-balancing strategy or even implement your own one!