When Quarkus meets LangChain4j

Large language models (LLMs) are reshaping the world of software, altering the way we interact with users and develop business logic.
Popularized by OpenAI's ChatGPT, LLMs are now available in many flavors and sizes. The Hugging-Face platform references hundreds of them, and major tech companies like Facebook, Google, Microsoft, Amazon and IBM are also providing their own models.
LLMs are not a new concept. They have been around for a while, but they were not as powerful or as accessible they became when OpenAI made ChatGPT API’s publically available. Since then the Quarkus team have been thinking about what it would mean to integrate LLMs in the Quarkus ecosystem. The talk Java Meets AI from Lize Raes at Devoxx 2023 has been a great source of inspiration.
Since, the Quarkus team, in collaboration with Dmytro Liubarskyi and the LangChain4j team, has been working on an extension to integrate LLMs in Quarkus applications. This extension is based on the LangChain4j library, which provides a common API to interact with LLMs. The LangChain4j project is a Java re-implementation of the famous langchain library.
In this blog post, we will see how to use the just released quarkus-langchain4j 0.1 extension to integrate LLMs in Quarkus applications. This extension is an exploration to understand how LLMs can be used in Quarkus applications.
We recorded a live Fireside chat on this extension. You can watch it here, the blog continues below.
Visão geral
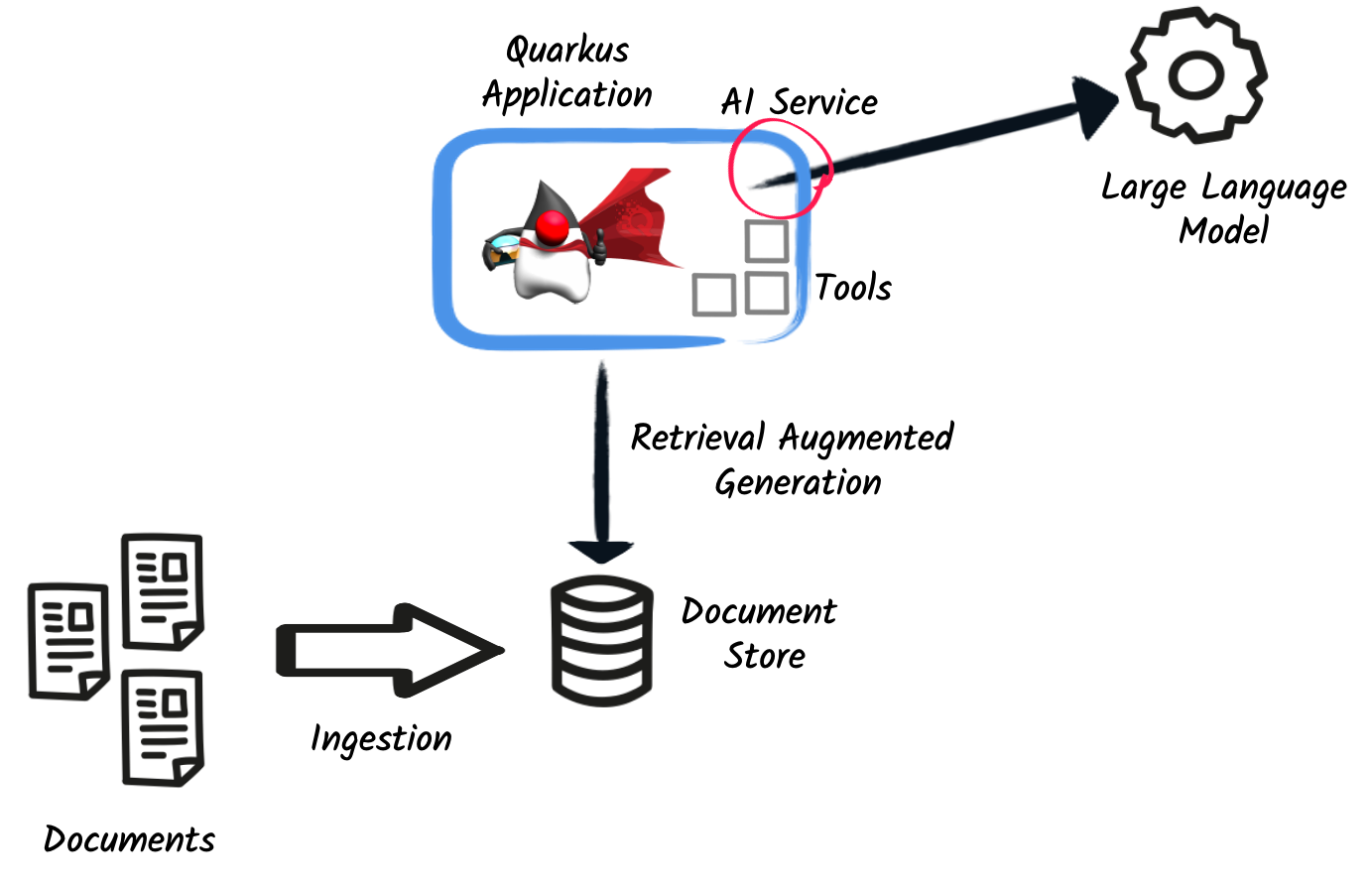
First, let’s have a look at the big picture. When integrating an LLM into a Quarkus application, you need to describe what you want the AI to do. Unlike traditional code, you are going to explain the behavior of the AI using natural language. Of course, there are a few techniques to tame the AI, but we will explore that later.
Strictly relying on the LLM’s knowledge might not be enough. Thus, the Quarkus LangChain4j extension provides two mechanisms to extend AI knowledge:
-
Tools - a tool lets the LLM execute actions in your application. For instance, you can use a tool to send an email, call a REST endpoint, or execute a database query. The LLM decides when to use the tool, the method parameters, and what to do with the result.
-
Document stores - LLMs are not good at remembering things. In addition, their context has a size limit. Thus, the extension provides a way to store and retrieve information from document stores. Before calling the LLM, the extension can ask for relevant documents in a document store and attach them to the context. The LLM can then use this data to make a decision. For instance, you can load spreadsheet data, reports, or data from a database.
The following diagram illustrates the interactions between the LLM, the tools, and the document stores:
Show me some code!
Alright, enough "bla bla", let’s see some code! We are going to use Open AI GPT-3.5 (be careful that it’s not the state-of-the-art model, but it’s good enough for this demo), give it some product reviews, and ask the LLM to classify them between positive and negative reviews. The full code is available in the quarkus-langchain4j repository.
First, we need the quarkus-langchain4j-openai extension:
<dependency>
<groupId>io.quarkiverse.langchain4j</groupId>
<artifactId>quarkus-langchain4j-openai</artifactId>
<version>0.1.0</version> <!-- Update to use the latest version -->
</dependency>Once we have the extension, it’s time to tell the LLM what we want to do. The Quarkus LangChain4J extension provides a declarative way to describe LLM interactions. The idea is the same as the Quarkus REST client. We model the interaction using an interface annotated with @RegisterAiService:
@RegisterAiService
public interface TriageService {
// methods.
}The rest of the application would be able to use the LLM by injecting the TriageService interface and calling the methods.
Speaking about methods, that’s where the magic happens. You will describe what you want the LLM to do using natural language. First, you start with @SystemMessage to define the role and scope. Then, you can use @UserMessage to describe the task.
@RegisterAiService
public interface TriageService {
@SystemMessage("""
You are working for a bank, processing reviews about
financial products. Triage reviews into positive and
negative ones, responding with a JSON document.
"""
)
@UserMessage("""
Your task is to process the review delimited by ---.
Apply sentiment analysis to the review to determine
if it is positive or negative, considering various languages.
For example:
- `I love your bank, you are the best!` is a 'POSITIVE' review
- `J'adore votre banque` is a 'POSITIVE' review
- `I hate your bank, you are the worst!` is a 'NEGATIVE' review
Respond with a JSON document containing:
- the 'evaluation' key set to 'POSITIVE' if the review is
positive, 'NEGATIVE' otherwise
- the 'message' key set to a message thanking or apologizing
to the customer. These messages must be polite and match the
review's language.
---
{review}
---
""")
TriagedReview triage(String review);
}Voilà! That’s all you need to do to describe the interaction with the LLM. The instructions follow a set of principles to shape the LLM response. Learn more about these techniques in the dedicated prompt engineering page.
Now, to call the LLM from the application code, just inject the TriageService and call the triage method:
@Path("/review")
public class ReviewResource {
@Inject
TriageService triage;
record Review(String review) {
// User text
}
@POST
public TriagedReview triage(Review review) {
return triage.triage(review.review());
}
}That’s it! The LLM is now integrated into the application. The TriageService interface is used as an ambassador to call the LLM. This declarative approach has many advantages:
-
Testability - you can easily mock the LLM by providing a fake implementation of the interface.
-
Observability - you can use the Quarkus metrics annotation to monitor the LLM methods.
-
Resilience - you can use the Quarkus fault-tolerance annotations to handle failures, timeouts, and other transient issues.
Tools and Document loader
The previous example is a bit simplistic. In the real world, you will need to extend the LLM knowledge with tools and document stores. The @RegisterAiService annotation lets you define the tools and document stores to use.
Tools
Tools are methods that the LLM can invoke.
To declare a tool, just use the @Tool annotation on a bean method:
@ApplicationScoped
public class CustomerRepository implements PanacheRepository<Customer> {
@Tool("get the customer name for the given customerId")
public String getCustomerName(long id) {
return find("id", id).firstResult().name;
}
}In this example, we are using the Panache repository pattern to access the database. We have a specific method annotated with @Tool to retrieve the customer name. When the LLM needs to get the customer name, it instructs Quarkus to call this method and receives the result.
Obviously, it’s not a good idea to expose every operation to the LLM. So, in addition to @Tool, you need to list the set of tools you allow the LLM to invoke in the @RegisterAiService annotation:
@RegisterAiService(
tools = { TransactionRepository.class, CustomerRepository.class },
chatMemoryProviderSupplier = RegisterAiService.BeanChatMemoryProviderSupplier.class
)
public interface FraudDetectionAi {
// ...
}The chatMemoryProviderSupplier configuration may raise questions. When using tools, a sequence of messages unfolds behind the scenes. It becomes necessary to configure the AI service’s memory to adeptly track these interactions. The chatMemoryProviderSupplier allows configuring how the memory is handled. The value BeanChatMemoryProviderSupplier.class instructs Quarkus to look for a ChatMemoryProvider bean, like the following:
@RequestScoped
public class ChatMemoryBean implements ChatMemoryProvider {
Map<Object, ChatMemory> memories = new ConcurrentHashMap<>();
@Override
public ChatMemory get(Object memoryId) {
return memories.computeIfAbsent(memoryId,
id -> MessageWindowChatMemory.builder()
.maxMessages(20)
.id(memoryId)
.build()
);
}
@PreDestroy
public void close() {
memories.clear();
}
}At the moment, only the OpenAI models support tools.
Document stores
Document stores are a way to extend the LLM knowledge with your own data. This approach - called Retrieval Augmented Generation (RAG) - requires two processes:
- The ingestion process
-
you ingest documents into a document store. The documents are not stored as-is, but an embedding is computed. This embedding is a vector representation of the document.
- The RAG process
-
in the Quarkus application, you need to declare the document store and the embedding to use. Thus, before calling the LLM, it retrieves the relevant documents from the store (that’s where the vector representation is useful) and attaches them to the LLM context (which essentially means adding the retrieved information from the document to the user message).
The Quarkus LangChain4j extension provides facilities for both processes.
The following code shows how to ingest a document into a Redis document store:
@ApplicationScoped
public class IngestorExample {
/**
* The embedding store (the database).
* The bean is provided by the quarkus-langchain4j-redis extension.
*/
@Inject
RedisEmbeddingStore store;
/**
* The embedding model (how the vector of a document is computed).
* The bean is provided by the LLM (like openai) extension.
*/
@Inject
EmbeddingModel embeddingModel;
public void ingest(List<Document> documents) {
var ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.embeddingModel(embeddingModel)
.documentSplitter(recursive(500, 0))
.build();
ingestor.ingest(documents);
}
}Then, generally, in another application, you can use the populated document store to extend the LLM knowledge. First, create a bean implementing the Retriever<TextSegment> interface:
@ApplicationScoped
public class RetrieverExample implements Retriever<TextSegment> {
private final EmbeddingStoreRetriever retriever;
RetrieverExample(RedisEmbeddingStore store, EmbeddingModel model) {
retriever = EmbeddingStoreRetriever.from(store, model, 20);
}
@Override
public List<TextSegment> findRelevant(String s) {
return retriever.findRelevant(s);
}
}Then, add the document store and the retriever to the @RegisterAiService annotation:
@RegisterAiService(
retrieverSupplier = RegisterAiService.BeanRetrieverSupplier.class
)
public interface MyAiService {
// ...
}
RegisterAiService.BeanRetrieverSupplier.class is a special value looking for the Retriever bean in the Quarkus application.
|
Final notes
This post presented the Quarkus LangChain4j extension. This is the first version of the extension, and we continue exploring and experimenting with approaches to integrate LLMs into Quarkus applications. We are looking for feedback and ideas to improve these integrations. We are working on removing some rough angles, and exploring other ways to integrate LLMs and to bring developer joy when integrating with LLMs.
This extension would not have been possible without the fantastic work from Dmytro Liubarskyi on the LangChain4j library. Our collaboration has allowed us to provide a Quarkus-friendly approach to integrate the library (including native compilation support) and shape a new way to integrate LLMs in Quarkus applications. The current design was tailored to enable Quarkus applications to use LLM easily. You can basically hook up any of your beans as tools or ingest data into a store. In addition, any of your bean can now interact with an LLM.
We are looking forward to continuing this collaboration and to see what you will build with this extension.